

Exemples d'applications 3D : jeu vidéo (gauche), CAO (centre), imagerie médicale (droite).
Les modèles 3D sont omniprésents dans de nombreux domaines :
Quelques exemples de ces applications sont présentés ci-dessous.
Exemples d'applications 3D : jeu vidéo (gauche), CAO (centre), imagerie médicale (droite).
La création et la manipulation de contenus 3D restent cependant des tâches complexes et coûteuses :
Les outils automatiques basés sur l’IA générative commencent à émerger, mais restent très peu contrôlables et avec un coût environnemental important. Ils sont encore largement expérimentaux pour de vraies productions. La contrôlabilité, la qualité et l’efficience restent des défis majeurs.
L’informatique graphique (Computer Graphics) désigne l’ensemble des sciences et techniques permettant de générer et manipuler des données visuelles :
Les applications sont nombreuses : loisirs, design, simulation de phénomènes naturels, médicaux, biologiques, etc.
L’informatique graphique se structure autour de trois grands domaines :
Modélisation (Modeling) : création et représentation de formes 3D. Cela recouvre la conception de la géométrie des objets (leur forme, leur structure) ainsi que leurs attributs visuels (textures, matériaux). La modélisation peut être manuelle (artiste utilisant un logiciel comme Blender ou Maya) ou procédurale (génération algorithmique de formes).
Animation : mise en mouvement des objets et personnages au cours du temps. L’animation englobe aussi bien les techniques cinématiques (déplacement explicite des objets image par image ou par interpolation de poses clés) que les techniques physiques (simulation de forces, gravité, collisions, fluides, tissus, etc. qui génèrent le mouvement automatiquement à partir de lois physiques).
Synthèse d’images / Rendu (Rendering) : génération d’images 2D à partir d’une scène 3D. Le rendu prend en entrée la description de la géométrie, des matériaux, des lumières et de la caméra, puis calcule l’image résultante. On distingue le rendu temps réel (interactif, typiquement \(\geq\) 25-60 images par seconde, utilisé dans les jeux vidéos et la visualisation) et le rendu hors-ligne (photo-réaliste, pouvant prendre de quelques secondes à plusieurs heures par image, utilisé au cinéma et en architecture).
Ces trois domaines sont illustrés ci-dessous.



Modélisation (gauche), animation (centre) et rendu (droite).
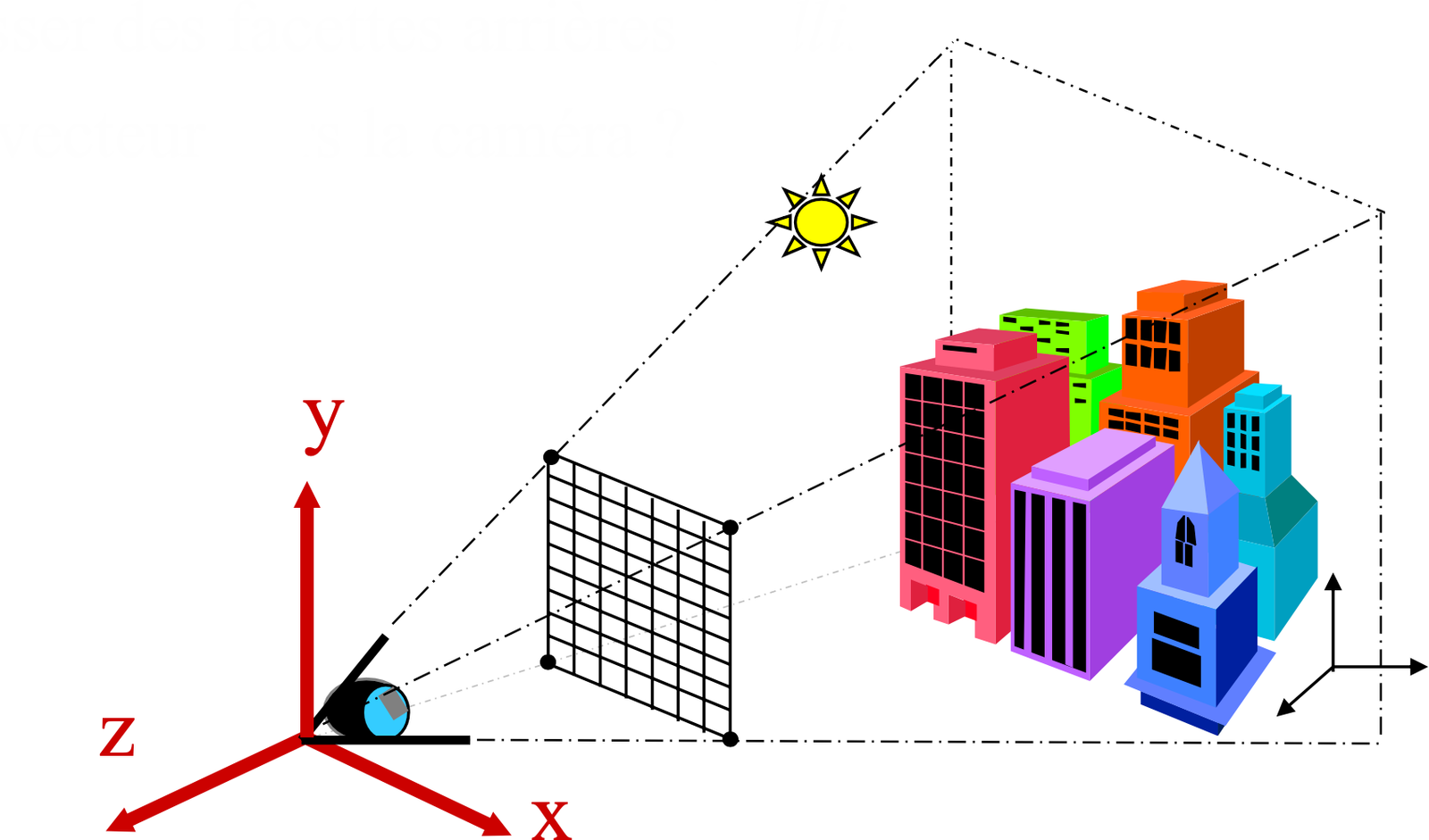
Une scène 3D est décrite par trois composantes fondamentales :
Modèle 3D : une surface ou un volume représentant les objets de la scène. Chaque objet possède une géométrie (forme) et des attributs visuels (couleur, matériau, texture). La scène peut contenir un ou plusieurs objets, chacun positionné et orienté dans un espace 3D commun appelé espace monde (world space).
Source de lumière : une ou plusieurs sources éclairant la scène. Une source de lumière est caractérisée par sa position (ou direction), son intensité et sa couleur. Les types courants incluent les lumières ponctuelles (émission depuis un point), les lumières directionnelles (rayons parallèles, simulant le soleil), et les lumières surfaciques (émission depuis une surface, pour des ombres plus douces). L’interaction entre la lumière et les matériaux des objets détermine l’apparence visuelle de la scène.
Caméra : le point de vue depuis lequel la scène est observée. La caméra est définie par sa position dans l’espace, son orientation (direction de visée), et ses paramètres optiques (champ de vision, focale, ratio d’aspect). Elle détermine quels objets sont visibles et comment ils sont projetés sur l’image finale.
La sortie du processus de rendu est une image 2D correspondant à ce que la caméra “voit” de la scène 3D. Le schéma suivant résume l’agencement de ces composantes.
Un enjeu fondamental de l’informatique graphique est de donner l’illusion de la profondeur et du volume sur un écran qui est intrinsèquement un support 2D. Plusieurs phénomènes visuels contribuent à cette perception.
Les objets éloignés apparaissent plus petits que les objets proches. Deux lignes parallèles dans la scène convergent vers un point de fuite sur l’image. Cet effet est directement lié à la projection perspective réalisée par la caméra (voir section sur les coordonnées généralisées).


Projection orthographique (gauche) vs projection perspective (droite).
La couleur d’un point de la surface varie en fonction de l’orientation de cette surface par rapport à la source lumineuse. Une surface faisant face à la lumière apparaît claire, tandis qu’une surface tournée de l’autre côté apparaît sombre. Ce dégradé de luminosité, appelé ombrage (shading), donne des indices essentiels sur la courbure et le volume des objets. Par opposition, un objet affiché avec une couleur uniforme (sans ombrage) paraît plat, comme un disque plutôt qu’une sphère.
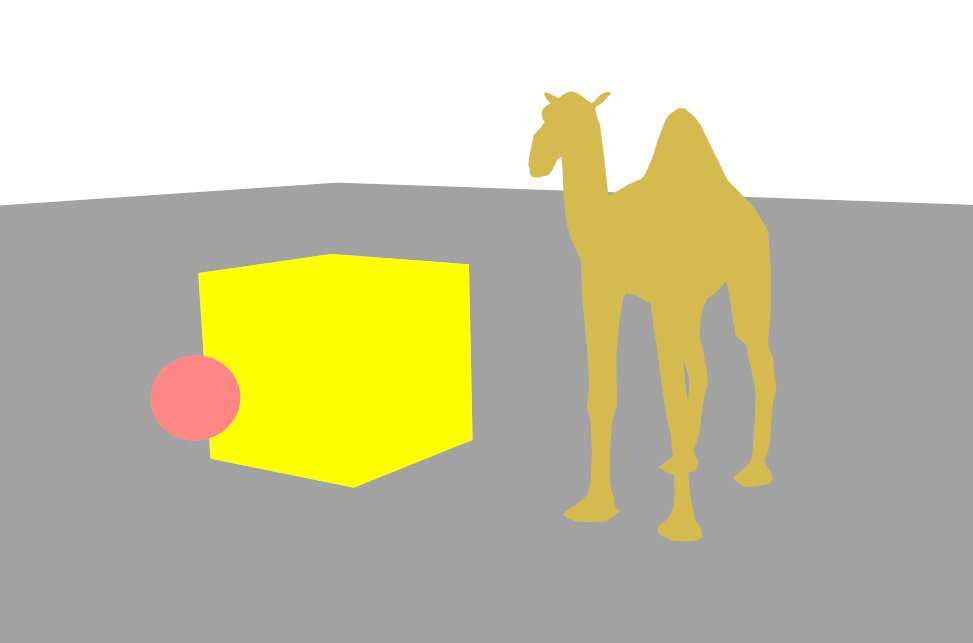

Couleur uniforme (gauche) vs illumination diffuse (droite) : l'ombrage révèle la géométrie.
Les objets proches masquent les objets situés derrière eux. Ce phénomène simple mais puissant fournit un indice direct de l’ordre en profondeur des objets dans la scène.
L’ombre qu’un objet projette sur un autre objet ou sur le sol ancre visuellement l’objet dans la scène et donne des informations sur sa position relative et la direction de la lumière.
Une image est une grille 2D de pixels de dimension \(N_x \times N_y\).
Autres formats courants :
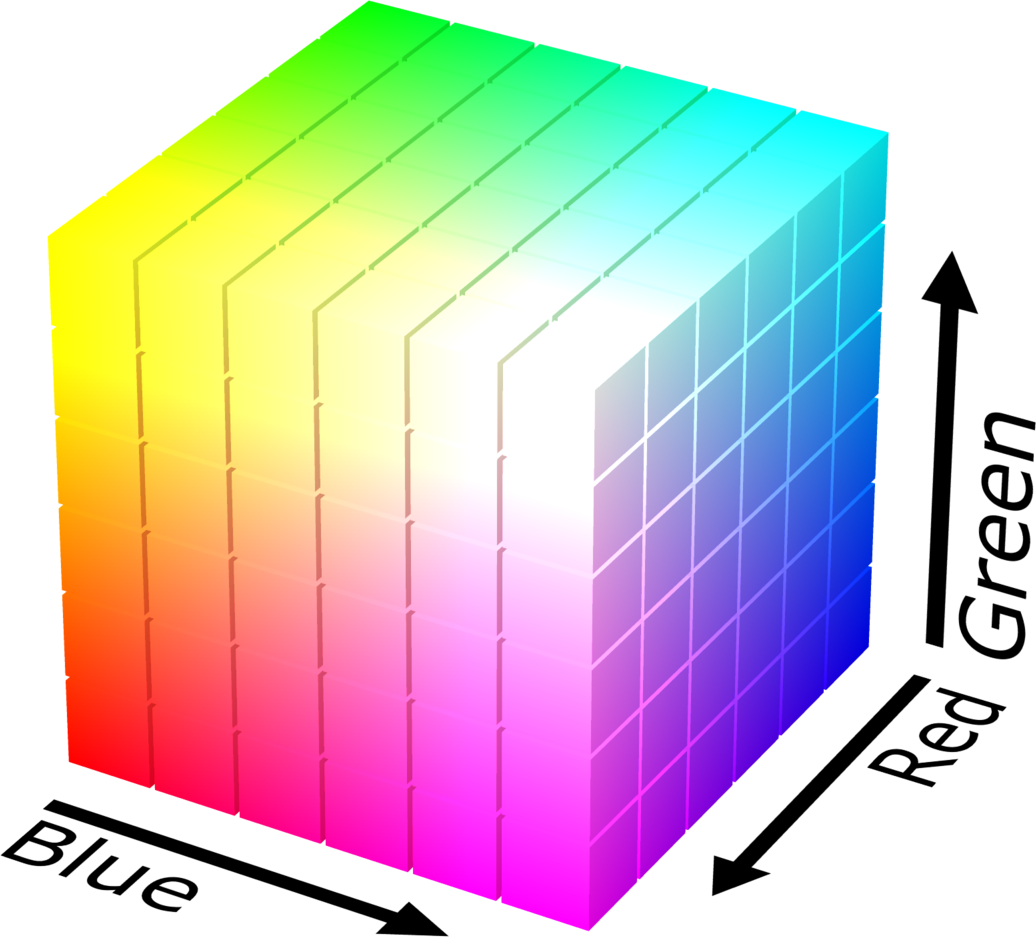
Remarque : l’espace RGB n’est pas perceptuellement uniforme (deux couleurs proches en distance RGB ne sont pas nécessairement proches visuellement). Le cube RGB est représenté sur la figure ci-dessous.
Un objet 3D peut être représenté de deux manières fondamentales :
Volume : description complète de l’objet, incluant l’intérieur. On peut par exemple associer une densité, une température ou tout autre attribut physique en chaque point du volume. Cette représentation est indispensable en imagerie médicale (IRM, scanner), en simulation de fluides (fumée, nuages) et en physique des matériaux. Cependant, elle est très coûteuse en mémoire : un volume de résolution \(256^3\) contient déjà plus de 16 millions de voxels (pixel volumique).
Surface : uniquement la partie extérieure et visible de l’objet. Seule la “peau” de l’objet est décrite, sans information sur l’intérieur. Cette représentation est beaucoup plus économe en mémoire et surtout bien plus efficace pour le rendu sur GPU, car seule la surface contribue à l’image finale.
En informatique graphique temps réel, on utilise majoritairement des représentations par surface. Les représentations volumiques sont réservées à des cas spécifiques (effets atmosphériques, données médicales, simulation physique). La figure suivante compare ces deux approches.
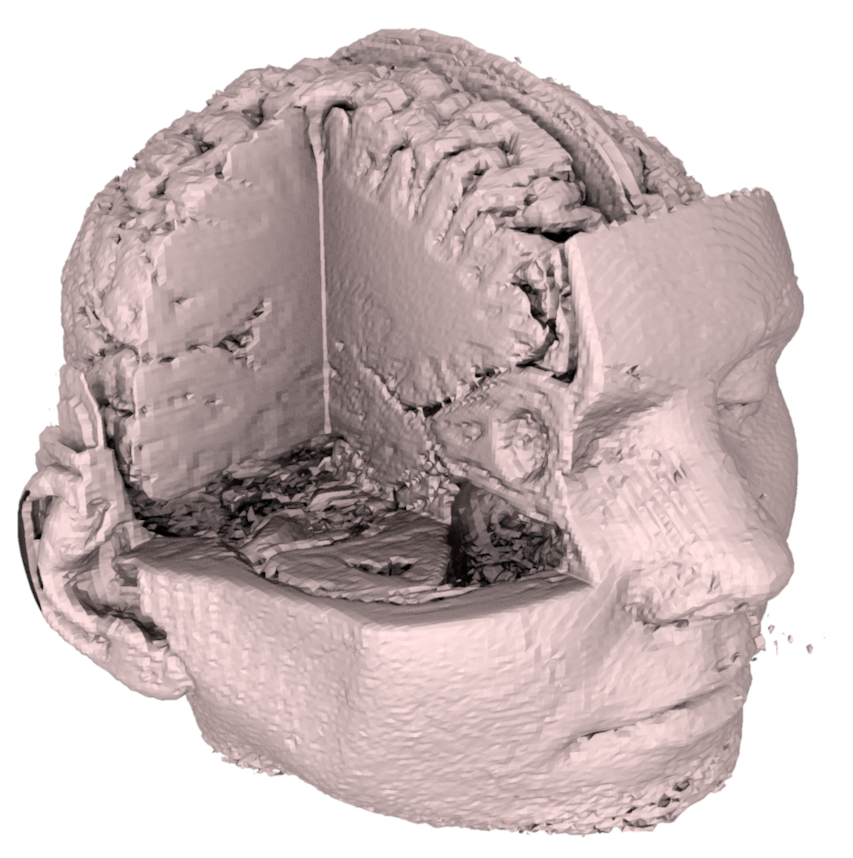
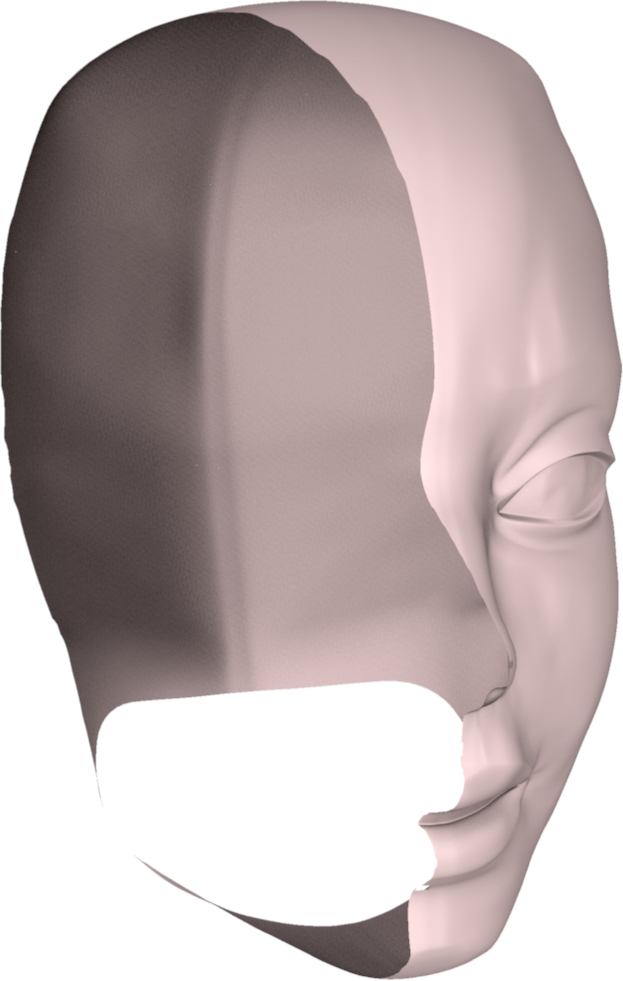
Représentation volumique (gauche) vs représentation surfacique (droite).
Il existe deux familles fondamentales de description mathématique d’une surface :
Les deux types de représentation sont comparés sur le schéma ci-dessous.


Surface explicite paramétrique (gauche) vs surface implicite (droite).
En pratique, pour des formes complexes comme un personnage ou un véhicule, aucune formule analytique simple ne peut décrire la surface. On recourt alors à des approximations discrètes.
En pratique, les surfaces arbitraires sont rarement décrites par une seule fonction analytique. On utilise des approximations par morceaux à l’aide de primitives et d’éléments discrets.
Les propriétés idéales d’une description sont :
Exemples de modèles :
Les cartes graphiques sont spécialisées pour le rendu de maillages triangulaires.
Le lancé de rayons simule le parcours physique de la lumière dans la scène. Le principe de base est le suivant : pour chaque pixel de l’image, on lance un rayon depuis la caméra à travers ce pixel et on cherche le premier objet de la scène que ce rayon intersecte. Une fois le point d’intersection trouvé, on calcule sa couleur en fonction de l’éclairage, du matériau et éventuellement des réflexions et réfractions (en lançant récursivement de nouveaux rayons).
En pratique, les rayons sont souvent tracés dans le sens inverse de la lumière (de la caméra vers la scène), car la grande majorité des rayons émis par une source lumineuse n’atteignent jamais la caméra. Ce traçage inversé est beaucoup plus efficace.
Avantages :
Inconvénients :
Le principe est résumé sur le schéma suivant.

L’approche par rasterization adopte une stratégie radicalement différente du ray tracing. Au lieu de partir de chaque pixel et de chercher quel objet est visible, on part de chaque objet (triangle) et on détermine quels pixels il recouvre. Cette approche suppose que la scène est composée de triangles. Le processus se déroule en deux étapes :
Projection : chaque sommet de triangle est projeté depuis l’espace 3D sur le plan 2D de la caméra. Cette opération est réalisée par une multiplication matricielle dans un espace projectif : \(p' = M \, p\), où \(M\) est la matrice combinant la transformation de la scène, le placement de la caméra et la projection perspective. Cette opération est extrêmement rapide car elle se résume à un produit matrice-vecteur par sommet.
Rasterization : une fois les triangles projetés en 2D, chaque triangle est “rempli” pixel par pixel. Pour chaque pixel couvert par le triangle, on calcule ses coordonnées barycentriques et on interpole les attributs des sommets (couleur, normale, coordonnées de texture, etc.) pour obtenir la valeur au pixel. Chaque pixel ainsi traité est appelé un fragment.
Ces deux étapes sont illustrées ci-dessous.


Projection des sommets sur le plan caméra (gauche) et rasterization des triangles en pixels (droite).
Un mécanisme de z-buffer (tampon de profondeur) permet de gérer l’occultation : pour chaque pixel, on ne conserve que le fragment le plus proche de la caméra, assurant que les objets en avant masquent ceux en arrière.
Avantages :
Inconvénients :
La rasterization est le standard du rendu temps réel sur GPU. C’est l’approche utilisée dans tous les jeux vidéos, les applications de visualisation interactive et les logiciels de CAO.
Un maillage triangulaire est la représentation la plus simple et la plus répandue pour approximer une surface continue par un ensemble de triangles. Plus le nombre de triangles est élevé, plus l’approximation est fidèle à la surface originale, mais plus le coût de stockage et de rendu est important. En pratique, un modèle 3D typique dans un jeu vidéo contient de quelques milliers à plusieurs centaines de milliers de triangles. Un modèle haute résolution pour le cinéma peut contenir plusieurs millions de triangles.
Un maillage est décrit par trois types d’éléments :
 Sommets (vertices) : les points 3D qui forment les
coins des triangles. L’ensemble des sommets est noté \(\mathcal{V} = (p_1, \dots, p_{N_v})\) avec
\(p_i = (x_i, y_i, z_i) \in
\mathbb{R}^3\). Chaque sommet peut porter des attributs
supplémentaires : une normale (direction perpendiculaire à la surface en
ce point), une couleur, des coordonnées de texture, etc.
Sommets (vertices) : les points 3D qui forment les
coins des triangles. L’ensemble des sommets est noté \(\mathcal{V} = (p_1, \dots, p_{N_v})\) avec
\(p_i = (x_i, y_i, z_i) \in
\mathbb{R}^3\). Chaque sommet peut porter des attributs
supplémentaires : une normale (direction perpendiculaire à la surface en
ce point), une couleur, des coordonnées de texture, etc.
 Faces : chaque face est un triangle défini par un
triplet d’indices de sommets \(\mathcal{F} =
(f_1, \dots, f_{N_f})\) avec \(f_i =
(p_{i_1}, p_{i_2}, p_{i_3})\). Les faces définissent la
connectivité (ou topologie) du maillage, c’est-à-dire
comment les sommets sont reliés entre eux.
Faces : chaque face est un triangle défini par un
triplet d’indices de sommets \(\mathcal{F} =
(f_1, \dots, f_{N_f})\) avec \(f_i =
(p_{i_1}, p_{i_2}, p_{i_3})\). Les faces définissent la
connectivité (ou topologie) du maillage, c’est-à-dire
comment les sommets sont reliés entre eux.
 Arêtes (Edges) (optionnel) : segments reliant deux
sommets adjacents \(\mathcal{E} = (e_1, \dots,
e_{N_e})\) avec \(e_i = (p_{i_1},
p_{i_2})\). Les arêtes ne sont pas toujours stockées
explicitement car elles peuvent être déduites des faces, mais elles sont
utiles pour certains algorithmes (subdivision, simplification,
etc.).
Arêtes (Edges) (optionnel) : segments reliant deux
sommets adjacents \(\mathcal{E} = (e_1, \dots,
e_{N_e})\) avec \(e_i = (p_{i_1},
p_{i_2})\). Les arêtes ne sont pas toujours stockées
explicitement car elles peuvent être déduites des faces, mais elles sont
utiles pour certains algorithmes (subdivision, simplification,
etc.).
Des exemples concrets de maillages sont visibles ci-dessous.
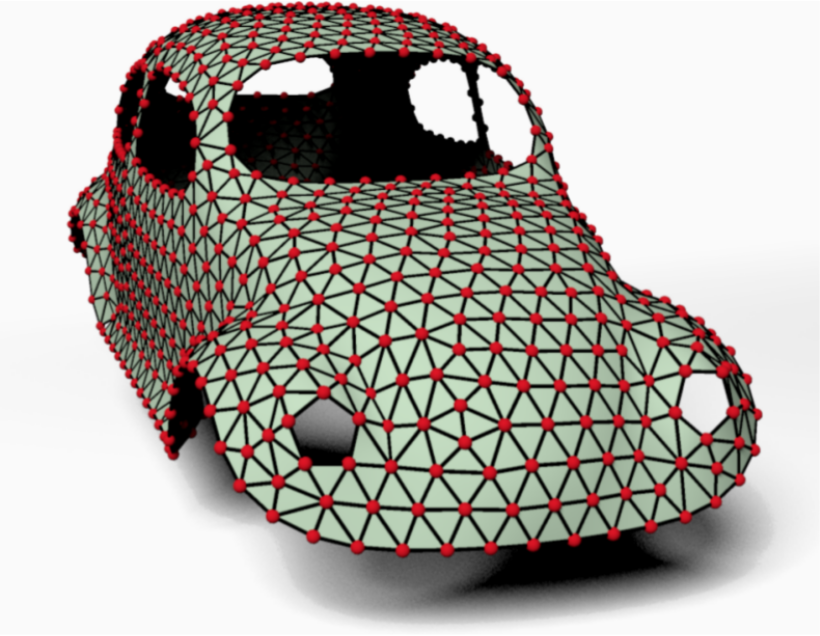

Exemples de maillages triangulaires : modèle de voiture (gauche) et modèle de dragon (droite).
Un triangle \(T\) est défini par trois sommets \((p_1, p_2, p_3)\). Le triangle est l’élément de base de la rasterization et possède des propriétés mathématiques très utiles que nous détaillons ci-dessous.
Tout point \(p\) à l’intérieur du triangle peut être exprimé comme une combinaison linéaire des deux arêtes issues de \(p_1\) :
\[ p \in T \Leftrightarrow S(u,v) = p_1 + u\,(p_2 - p_1) + v\,(p_3 - p_1), \quad u \geq 0, \; v \geq 0, \; u+v \leq 1 \]
Les paramètres \((u,v)\) forment un système de coordonnées local sur le triangle. Le sommet \(p_1\) correspond à \((0,0)\), \(p_2\) à \((1,0)\) et \(p_3\) à \((0,1)\).
Une manière équivalente et souvent plus pratique de paramétrer un triangle est d’utiliser les coordonnées barycentriques \((\alpha, \beta, \gamma)\) :
\[ p \in T \Leftrightarrow p = \alpha \, p_1 + \beta \, p_2 + \gamma \, p_3, \quad \alpha, \beta, \gamma \in [0,1], \; \alpha + \beta + \gamma = 1 \]
Les coordonnées barycentriques ont une interprétation géométrique intuitive : \(\alpha\) représente le “poids” ou l’influence du sommet \(p_1\) sur le point \(p\). Plus \(p\) est proche de \(p_1\), plus \(\alpha\) est grand (proche de 1) et plus \(\beta\) et \(\gamma\) sont petits. Aux sommets, on a respectivement \((\alpha, \beta, \gamma) = (1,0,0)\), \((0,1,0)\) et \((0,0,1)\). Au barycentre du triangle, les trois coordonnées valent \(1/3\).
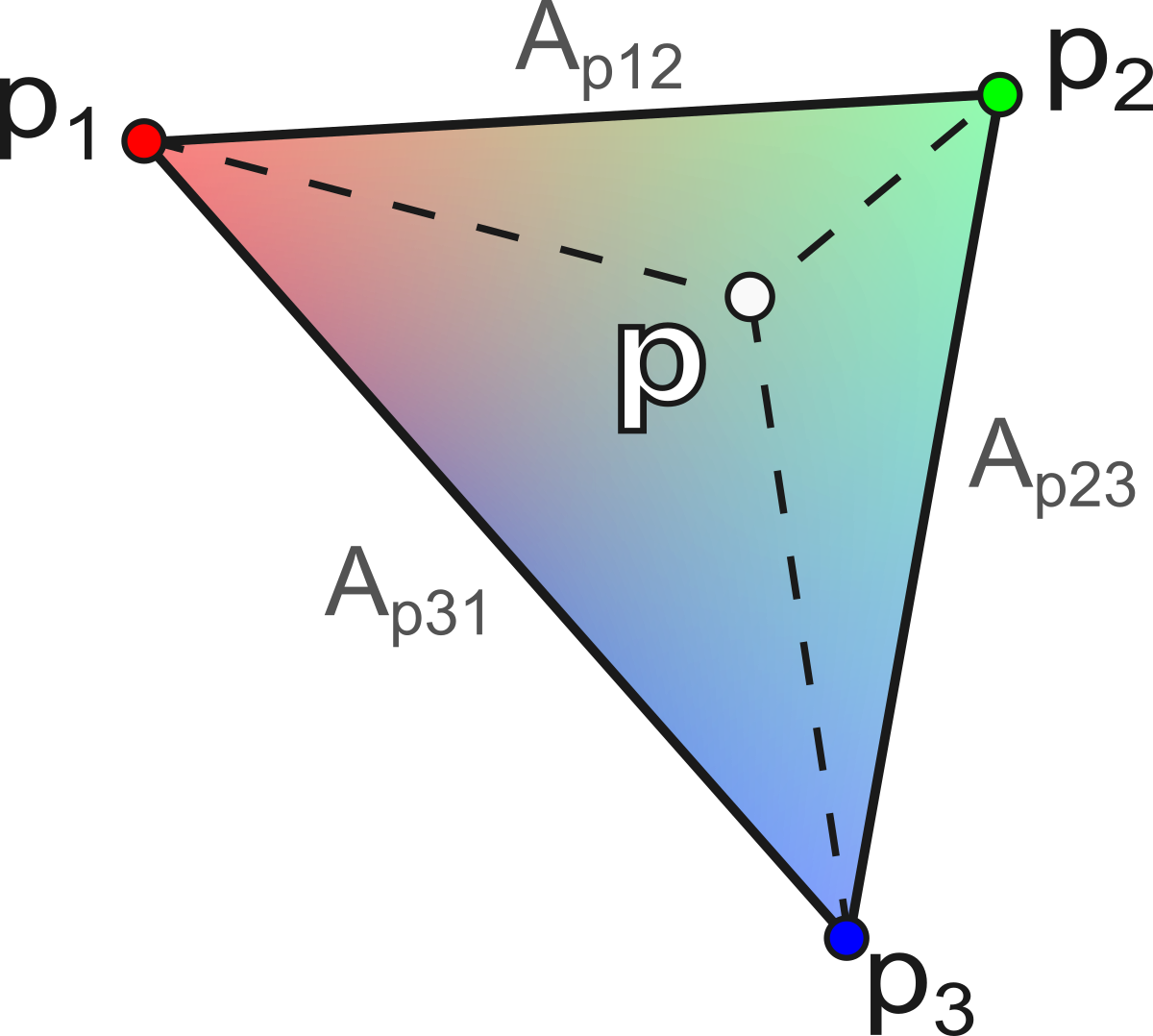
Le calcul des coordonnées barycentriques pour un point \(p\) se fait via le rapport des aires des sous-triangles :
\[ \alpha = \frac{A_{p23}}{A_{123}}, \quad \beta = \frac{A_{p31}}{A_{123}}, \quad \gamma = \frac{A_{p12}}{A_{123}} \]
avec \(A_{123} = \frac{1}{2} \| (p_2 - p_1) \times (p_3 - p_1) \|\) l’aire totale du triangle, et \(A_{p23}\), \(A_{p31}\), \(A_{p12}\) les aires des sous-triangles formés par \(p\) avec les arêtes opposées :
\[ \begin{aligned} A_{p23} &= \tfrac{1}{2} \| (p_2 - p) \times (p_3 - p) \| \\ A_{p31} &= \tfrac{1}{2} \| (p_3 - p) \times (p_1 - p) \| \\ A_{p12} &= \tfrac{1}{2} \| (p_1 - p) \times (p_2 - p) \| \end{aligned} \]
Cette construction géométrique est illustrée sur la figure ci-dessous.
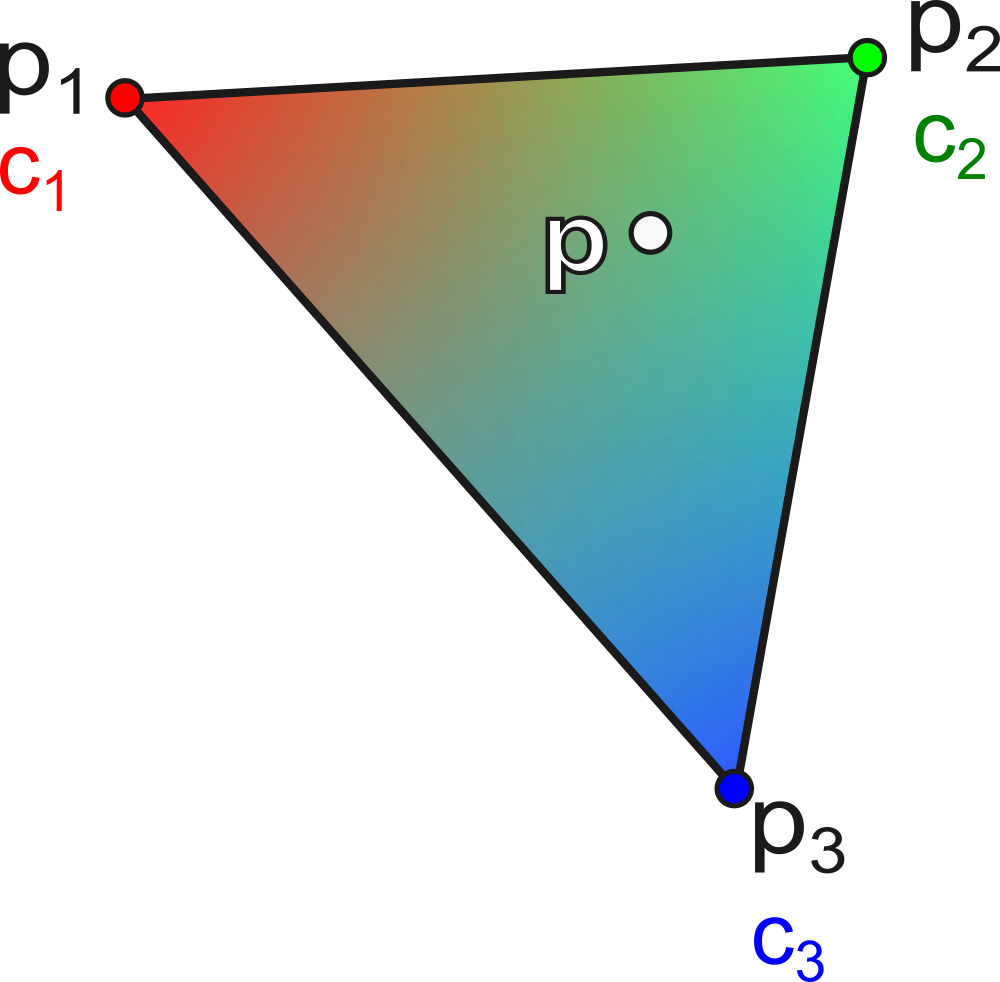
Soit un triangle \(T\) avec des couleurs \((c_1, c_2, c_3)\) associées aux sommets \((p_1, p_2, p_3)\). La couleur interpolée en un point \(p\) intérieur au triangle est :
\[ c(p) = \alpha \, c_1 + \beta \, c_2 + \gamma \, c_3 \]
où \((\alpha, \beta, \gamma)\) sont les coordonnées barycentriques de \(p\).
Cette interpolation est fondamentale en rendu : elle est utilisée pour interpoler les couleurs, les normales, les coordonnées de texture, etc., à l’intérieur de chaque triangle. Un exemple d’interpolation de couleurs est montré ci-dessous.
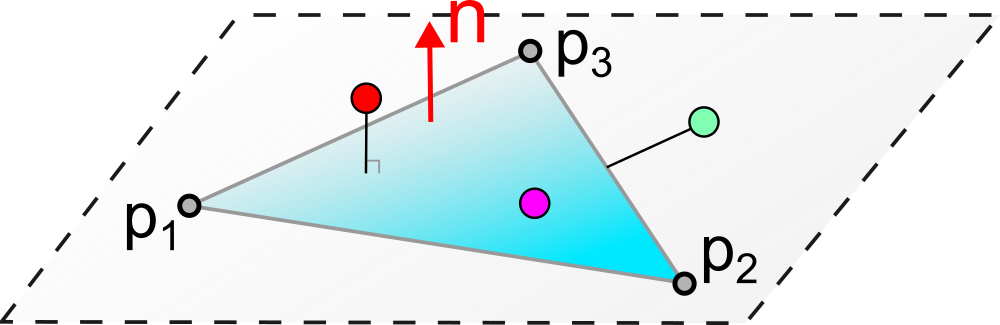
Pour tester si un point \(p\) est à l’intérieur d’un triangle \(T = (p_1, p_2, p_3)\) :
Condition nécessaire : \(p\) doit être dans le plan du triangle. On vérifie que \((p - p_1) \cdot n = 0\) avec \(n = (p_2 - p_1) \times (p_3 - p_1)\) (normale au triangle).
Condition suffisante : calcul des coordonnées barycentriques \((\alpha, \beta, \gamma)\). On vérifie que \(0 \leq \alpha, \beta, \gamma \leq 1\) et \(\alpha + \beta + \gamma = 1\).
Le principe de ce test est représenté sur le schéma suivant.
Considérons un tétraèdre \((p_0, p_1, p_2, p_3)\) comme exemple.
1ère solution : soupe de triangles
Chaque triangle est décrit par ses trois coordonnées, sans partage de sommets :
triangles = [(0.0,0.0,0.0), (1.0,0.0,0.0), (0.0,0.0,1.0),
(0.0,0.0,0.0), (0.0,0.0,1.0), (0.0,1.0,0.0),
(0.0,0.0,0.0), (0.0,1.0,0.0), (1.0,0.0,0.0),
(1.0,0.0,0.0), (0.0,1.0,0.0), (0.0,0.0,1.0)]2ème solution : géométrie + connectivité (topologie)
On sépare les positions des sommets et les indices des faces :
geometry = [(0.0,0.0,0.0), (1.0,0.0,0.0), (0.0,1.0,0.0), (0.0,0.0,1.0)]
connectivity = [(0,1,3), (0,3,2), (0,2,1), (1,2,3)]Cette seconde approche est bien plus efficace en mémoire car les sommets partagés ne sont stockés qu’une seule fois. Dans l’exemple du tétraèdre, la première solution stocke \(4 \times 3 = 12\) triplets de coordonnées (soit 36 flottants), tandis que la seconde ne stocke que 4 sommets (12 flottants) plus 4 triplets d’indices (12 entiers). Pour des maillages de grande taille, le gain est considérable. C’est la représentation standard utilisée en pratique et par les APIs graphiques (OpenGL, Vulkan, etc.).
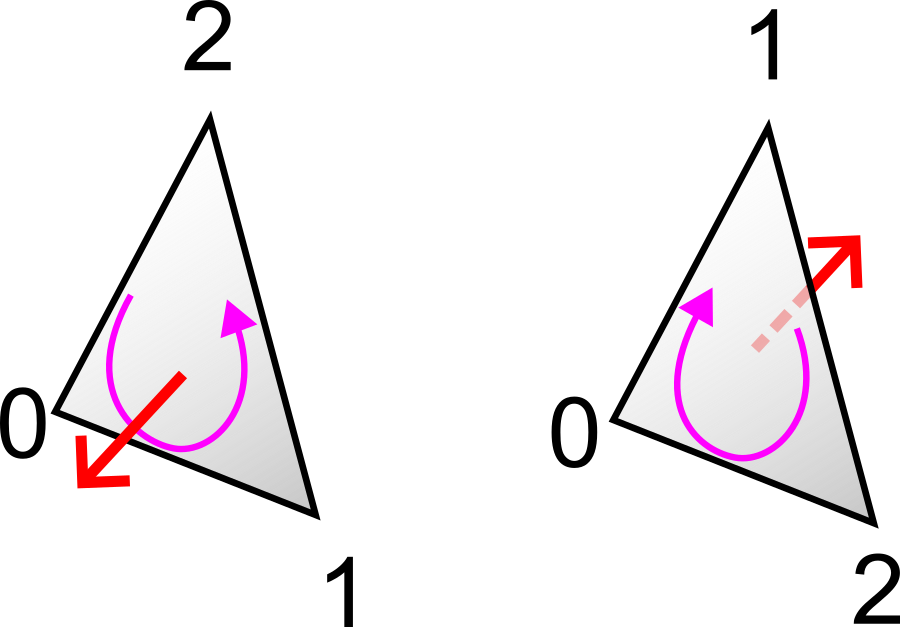
Remarque : l’ordre des indices dans chaque face définit l’orientation de la face. Par convention (dite de la main droite ou counterclockwise), lorsqu’on regarde la face depuis l’extérieur de l’objet, les sommets apparaissent dans le sens trigonométrique (anti-horaire). Cette orientation permet de calculer la normale sortante de la face par un produit vectoriel : \(n = (p_{i_2} - p_{i_1}) \times (p_{i_3} - p_{i_1})\). Le GPU utilise cette information pour le back-face culling : les triangles vus de dos (dont la normale est orientée à l’opposé de la caméra) ne sont pas affichés, ce qui réduit le coût de rendu de moitié environ. Cette convention est illustrée ci-dessous.
Le format OBJ (Wavefront) est l’un des formats texte les plus répandus pour stocker des maillages 3D. Sa simplicité le rend facile à lire et à écrire, aussi bien par des humains que par des programmes. Un fichier OBJ est un fichier texte où chaque ligne commence par un mot-clé suivi de valeurs :
v x y z : définit un sommet (vertex)
avec ses coordonnées 3D.vt u v : définit des coordonnées de
texture (pour plaquer une image sur la surface).vn x y z : définit une normale au
sommet (direction perpendiculaire à la surface, utilisée pour
l’ombrage).f v1 v2 v3 : définit une face
triangulaire par les indices de ses sommets. Les indices commencent à
1 (et non 0). On peut aussi référencer les normales et
textures avec la syntaxe
f v1/vt1/vn1 v2/vt2/vn2 v3/vt3/vn3.Exemple minimal (tétraèdre) :
v 0.0 0.0 0.0
v 1.0 0.0 0.0
v 0.0 1.0 0.0
v 0.0 0.0 1.0
f 1 2 4
f 1 4 3
f 1 3 2
f 2 3 4Les transformations affines sont les opérations fondamentales pour positionner, orienter et dimensionner des objets dans l’espace 3D. En informatique graphique, on les utilise en permanence : pour placer un objet dans la scène, pour animer un personnage (rotation des articulations), pour positionner la caméra, etc.
La translation déplace un point d’un vecteur constant \((t_x, t_y, t_z)\) :
\[ t(p) = (x + t_x, \; y + t_y, \; z + t_z) \]
La translation n’est pas une transformation linéaire (elle ne peut pas être représentée par une multiplication par une matrice \(3 \times 3\), car \(t(0) \neq 0\) en général). Cette propriété est à l’origine du besoin des coordonnées homogènes décrites plus loin.
Le scaling multiplie chaque coordonnée par un facteur d’échelle :
\[ s(p) = (s_x \, x, \; s_y \, y, \; s_z \, z) \]
En notation matricielle :
\[ S = \begin{pmatrix} s_x & 0 & 0 \\ 0 & s_y & 0 \\ 0 & 0 & s_z \end{pmatrix} \]
Si \(s_x = s_y = s_z\), le scaling est uniforme (l’objet garde ses proportions). Sinon, il est non uniforme (l’objet est déformé, par exemple étiré selon un axe).
Une rotation préserve les distances et les angles (c’est une isométrie). Elle est décrite par une matrice \(3 \times 3\) orthogonale :
\[ R = \begin{pmatrix} a & b & c \\ d & e & f \\ g & h & j \end{pmatrix}, \quad R\,R^T = I \text{ et } \det(R) = 1 \]
Les colonnes (et lignes) de \(R\) forment une base orthonormée : elles sont mutuellement orthogonales et de norme 1. La condition \(\det(R) = 1\) distingue les rotations des réflexions (qui ont un déterminant de \(-1\)).
Il existe plusieurs manières de paramétrer une rotation en 3D : angles d’Euler (trois angles successifs autour des axes), axe-angle (un axe et un angle de rotation autour de cet axe), ou quaternions (représentation à 4 composantes, très utilisée en animation pour son efficacité et l’absence de singularités).
Le cisaillement décale une coordonnée proportionnellement à une autre. Par exemple :
\[ sh_{xy}(p) = (x + \lambda \, y, \; y, \; z) \]
En notation matricielle :
\[ Sh_{xy} = \begin{pmatrix} 1 & \lambda & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{pmatrix} \]
Le cisaillement préserve les volumes (\(\det(Sh) = 1\)) mais ne préserve pas les angles (ce n’est pas une isométrie). Il est rarement utilisé volontairement en informatique graphique, mais peut apparaître comme sous-produit de certaines décompositions matricielles. Son effet géométrique est visible sur la figure suivante.

La rotation et le scaling sont des transformations linéaires, représentables par des matrices \(3 \times 3\). La translation, en revanche, est une transformation non linéaire qui ne peut pas être encodée directement par une matrice \(3 \times 3\).
Cela pose un problème pratique : en informatique graphique, on enchaîne en permanence des rotations, scalings et translations pour positionner les objets dans la scène. Par exemple, pour placer un objet dans le monde, on peut lui appliquer un scaling (pour ajuster sa taille), puis une rotation (pour l’orienter), puis une translation (pour le positionner). Si seules les rotations et scalings étaient des matrices, il faudrait maintenir deux représentations séparées (une matrice pour la partie linéaire et un vecteur pour la translation), ce qui compliquerait considérablement le code.
Idée : ajouter une coordonnée supplémentaire pour obtenir une représentation unifiée en 4D, dans laquelle toutes les transformations affines (y compris la translation) s’expriment comme des produits de matrices.
La transformation affine unifiée s’écrit alors comme un produit matriciel \(4 \times 4\) :
\[ \begin{pmatrix} p' \\ 1 \end{pmatrix} = \begin{pmatrix} L & t \\ 0 & 1 \end{pmatrix} \begin{pmatrix} p \\ 1 \end{pmatrix} = \begin{pmatrix} L\,p + t \\ 1 \end{pmatrix} \]
avec \(L\) la partie linéaire (\(3 \times 3\)) et \(t\) le vecteur de translation.
Pour un point \(p = (x, y)\), on ajoute une coordonnée : \(p = (x, y, 1)\).
La translation devient une opération linéaire :
\[ \begin{pmatrix} x + t_x \\ y + t_y \\ 1 \end{pmatrix} = \begin{pmatrix} 1 & 0 & t_x \\ 0 & 1 & t_y \\ 0 & 0 & 1 \end{pmatrix} \begin{pmatrix} x \\ y \\ 1 \end{pmatrix} \]
De même pour les rotations et le scaling, qui s’expriment comme des matrices \(3 \times 3\) en coordonnées homogènes 2D.
En 3D, on utilise des vecteurs à 4 composantes et des matrices \(4 \times 4\).
Toute séquence de translations, rotations et scalings peut se factoriser en un unique produit de matrices :
\[ M = T_0 \, R_0 \, S_0 \, T_1 \, R_1 \, S_1 \, \dots \]
L’avantage est considérable : quelle que soit la complexité de la chaîne de transformations, le résultat est toujours une unique matrice \(4 \times 4\). Appliquer cette transformation à un point revient à une seule multiplication matrice-vecteur. Cette propriété est exploitée massivement par le GPU, qui peut transformer des millions de sommets en appliquant la même matrice \(M\) à chacun d’eux en parallèle.
[Attention] : l’ordre des multiplications est important. Les transformations matricielles ne sont pas commutatives en général : \(T \, R \neq R \, T\). Par convention, la transformation la plus à droite est appliquée en premier. Ainsi, \(M = T \, R \, S\) signifie : d’abord scaling, puis rotation, puis translation.
L’intérêt des coordonnées généralisées est la différenciation naturelle entre points et vecteurs :
Point : \((x, y, z, \mathbf{1})\) — la translation s’applique.
\[ M \begin{pmatrix} p \\ 1 \end{pmatrix} = \begin{pmatrix} L & t \\ 0 & 1 \end{pmatrix} \begin{pmatrix} p \\ 1 \end{pmatrix} = \begin{pmatrix} L\,p + t \\ 1 \end{pmatrix} \]
Vecteur : \((x, y, z, \mathbf{0})\) — la translation ne s’applique pas.
\[ M \begin{pmatrix} v \\ 0 \end{pmatrix} = \begin{pmatrix} L & t \\ 0 & 1 \end{pmatrix} \begin{pmatrix} v \\ 0 \end{pmatrix} = \begin{pmatrix} L\,v \\ 0 \end{pmatrix} \]
Ce comportement est cohérent avec les opérations géométriques :
Cette distinction est résumée sur le schéma ci-dessous.

Considérons le cas d’un point généralisé avec coordonnée \(w \neq 1\) : \(p_{4D} = (x, y, z, w)\).
La “renormalisation” (ou projection) sur l’espace des points 3D donne : \(p_{3D} = (x/w, y/w, z/w, 1)\).
Exemple :
La somme de deux points donne :
\[ (x_1, y_1, z_1, 1) + (x_2, y_2, z_2, 1) = (x_1+x_2, \; y_1+y_2, \; z_1+z_2, \; 2) \]
Après homogénéisation :
\[ p_{3D} = \left(\frac{x_1+x_2}{2}, \; \frac{y_1+y_2}{2}, \; \frac{z_1+z_2}{2}, \; 1\right) \]
Ce qui correspond au barycentre des deux points.
L’intérêt de l’espace projectif est d’encoder des opérations rationnelles (comme la perspective) par une simple multiplication matricielle.
La perspective est modélisée par une division par la profondeur.
En 2D (projection 1D), pour un point \((x, y)\) projeté sur un plan focal à distance \(f\) :
\[ y' = f \, \frac{y}{x} \]
Ce modèle non linéaire s’écrit de manière linéaire en coordonnées homogènes :
\[ \begin{pmatrix} f \, y \\ x \end{pmatrix} = \begin{pmatrix} 0 & f \\ 1 & 0 \end{pmatrix} \begin{pmatrix} x \\ y \end{pmatrix} \]
Après homogénéisation (division par la dernière composante \(x\)), on obtient bien \(y' = f\,y/x\).
Les points réels (2D ou 3D) sont ceux dont la dernière composante vaut \(w = 1\) (obtenus après homogénéisation). Les vecteurs correspondent à \(w = 0\). Ce mécanisme de projection est représenté sur la figure suivante.

Un ordinateur dispose de deux processeurs principaux pour le calcul :
Les figures ci-dessous montrent l’aspect physique et l’architecture interne de ces deux types de processeurs.


CPU (gauche) et GPU (droite).
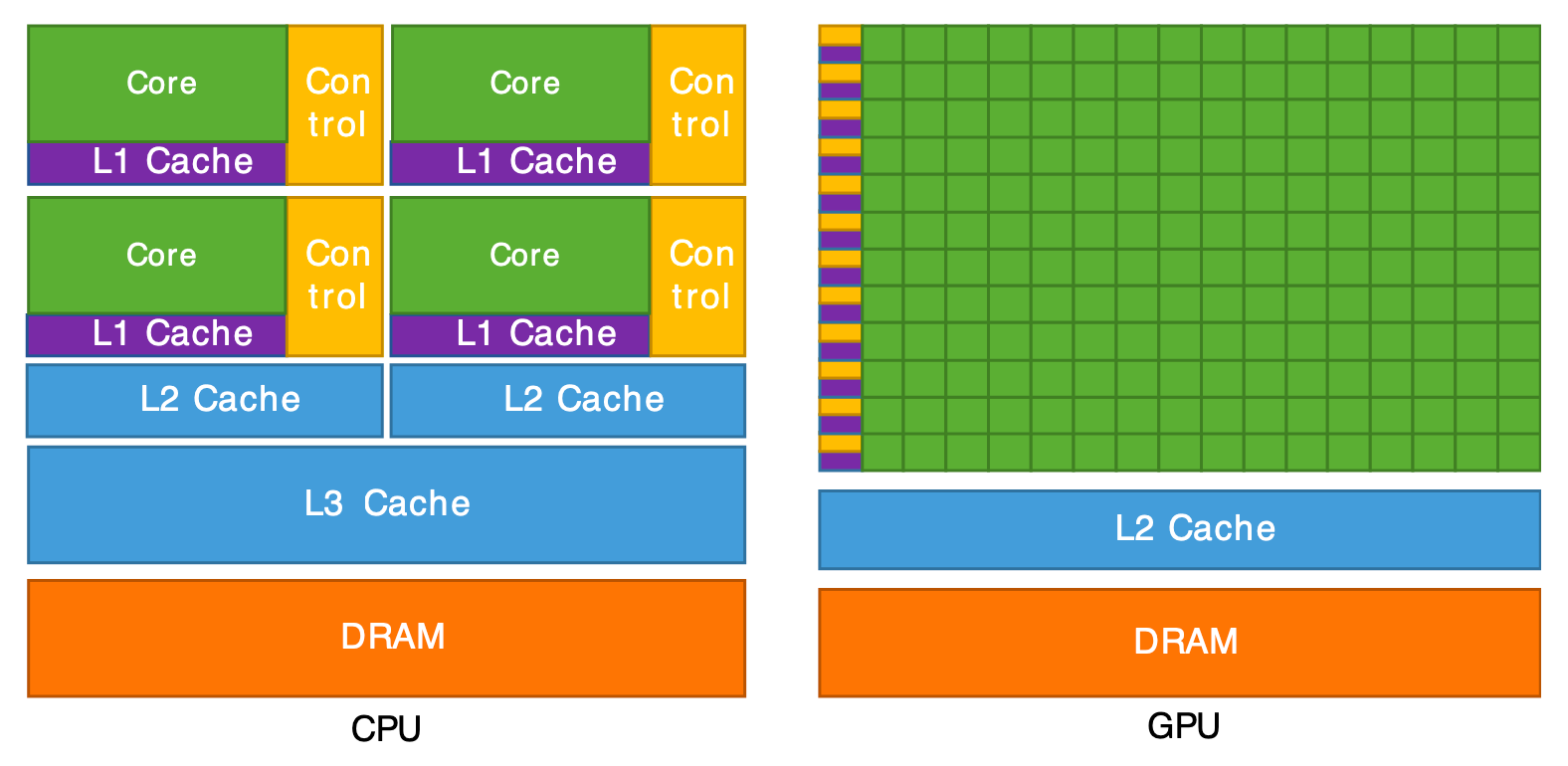
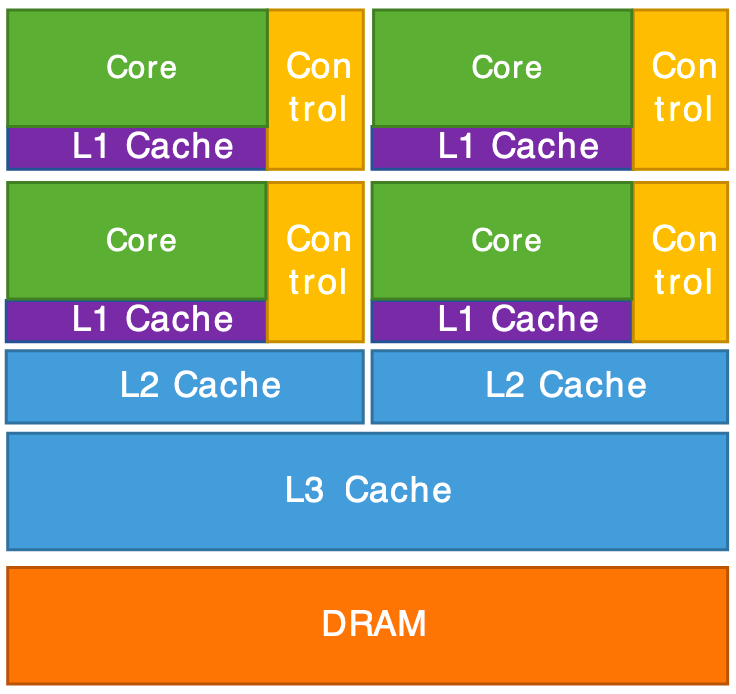
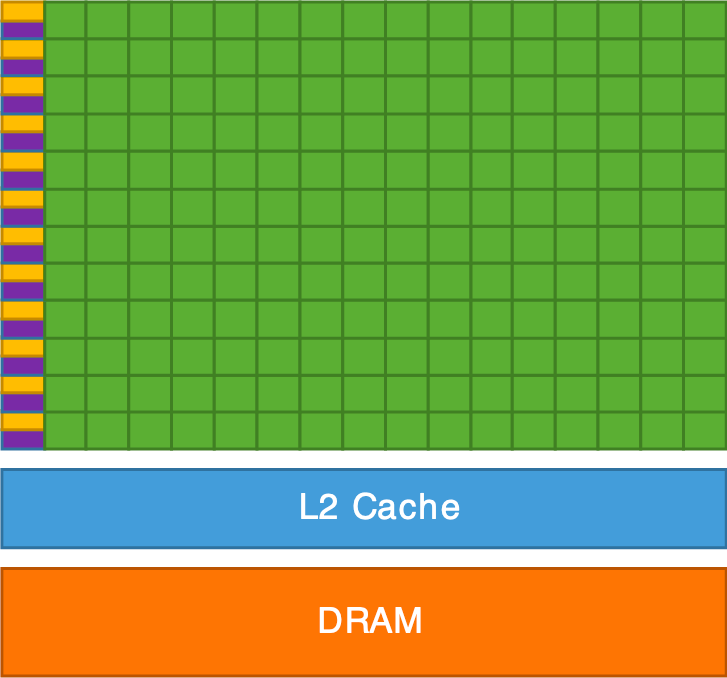
Architecture interne d'un CPU (gauche) et d'un GPU (droite).
Le GPU est en résumé un supercalculateur optimisé pour réaliser la même opération sur un grand nombre de données en parallèle. C’est exactement ce dont on a besoin pour le rendu graphique : transformer des millions de sommets (vertex shader) puis colorier des millions de pixels (fragment shader). Le CPU, quant à lui, se charge de la logique du programme (gestion de la scène, chargement des données, interactions utilisateur) et envoie les commandes de rendu au GPU.
OpenGL (Open Graphics Library) est une API (Application Programming Interface) pour communiquer avec le GPU, orientée graphique 3D.
Caractéristiques :
Autres APIs graphiques : Vulkan, WebGL, WebGPU, DirectX (Windows), Metal (Mac).
Le CPU et le GPU possèdent chacun leur propre mémoire (RAM et VRAM respectivement) et ne peuvent pas accéder directement à la mémoire de l’autre. Le processus de rendu nécessite donc une communication explicite entre les deux, orchestrée par l’API OpenGL. Ce processus suit trois grandes étapes :
Préparation des données (CPU) : le programme C++ (s’exécutant sur le CPU) charge ou calcule les données géométriques de la scène : positions des sommets, couleurs, normales, coordonnées de textures, indices de connectivité, etc. Ces données sont organisées dans des tableaux en RAM.
Envoi des données (CPU \(\rightarrow\) GPU) : les données sont transférées par blocs depuis la RAM vers la VRAM via des appels OpenGL. Ce transfert est relativement coûteux (le bus entre CPU et GPU a un débit limité), c’est pourquoi on cherche à le minimiser : idéalement, les données statiques (maillages qui ne changent pas) ne sont envoyées qu’une seule fois au démarrage. Seules les données qui changent à chaque image (matrices de transformation, paramètres d’animation) sont transmises à chaque frame.
Exécution des Shaders (GPU) : une fois les données en VRAM, le GPU exécute les programmes de shaders en parallèle sur chaque sommet puis sur chaque pixel. Le CPU n’intervient plus pendant cette phase : il se contente d’envoyer la commande “dessine” et le GPU fait le reste de manière autonome. Le résultat est l’image finale, stockée dans le framebuffer de la VRAM, qui est ensuite affichée à l’écran.
Les schémas suivants détaillent ce pipeline de communication.


Les shaders sont de petits programmes qui s’exécutent directement sur le GPU. Ils sont écrits dans un langage dédié appelé GLSL (OpenGL Shading Language), dont la syntaxe est proche du C. Le terme “shader” vient de “shading” (ombrage), car leur rôle initial était de calculer l’ombrage des surfaces, mais ils sont aujourd’hui utilisés pour toutes sortes de calculs graphiques.
La particularité fondamentale des shaders est qu’ils sont exécutés massivement en parallèle : le même programme est lancé simultanément sur des milliers de sommets ou de pixels. Le programmeur écrit le code pour un seul sommet ou pixel, et le GPU se charge de l’exécuter pour tous.
Deux types de shaders principaux interviennent dans le pipeline de rendu :
Exécuté une fois pour chaque sommet du maillage. Son rôle principal est de transformer la position du sommet depuis l’espace 3D de la scène vers l’espace 2D de l’écran (en appliquant les matrices de transformation et de projection). Il peut aussi calculer et transmettre des attributs (couleurs, normales transformées, coordonnées de texture, etc.) qui seront utilisés par le fragment shader.
#version 330 core
layout(location = 0) in vec4 position;
layout(location = 1) in vec4 color;
out vec4 vertexColor;
void main()
{
gl_Position = position;
vertexColor = color;
}Dans cet exemple :
#version 330 core : indique la version de GLSL utilisée
(correspondant à OpenGL 3.3).layout(location = 0) in vec4 position : déclare un
attribut d’entrée (la position du sommet), reçu depuis les données
envoyées par le CPU. Le location = 0 indique l’index du
buffer d’attributs.out vec4 vertexColor : déclare une variable de sortie
qui sera transmise au fragment shader. Entre le vertex shader et le
fragment shader, cette variable sera automatiquement interpolée par la
rasterization.gl_Position : variable spéciale prédéfinie par OpenGL,
dans laquelle le vertex shader doit écrire la position finale du sommet
(en coordonnées projetées).Exécuté une fois pour chaque pixel (fragment) couvert par un triangle après la rasterization. Son rôle est de déterminer la couleur finale du pixel en fonction des attributs interpolés (couleur, normale, coordonnées de texture), de l’éclairage, des textures, etc. C’est dans le fragment shader que l’on implémente les modèles d’illumination et les effets visuels.
#version 330 core
in vec4 vertexColor;
out vec4 fragColor;
void main()
{
fragColor = vertexColor;
}Dans cet exemple :
in vec4 vertexColor : variable d’entrée provenant du
vertex shader. Sa valeur a été automatiquement interpolée par la
rasterization entre les trois sommets du triangle courant, en utilisant
les coordonnées barycentriques du fragment.out vec4 fragColor : la couleur de sortie du fragment,
qui sera écrite dans l’image finale (framebuffer).En plus des attributs (propres à chaque sommet) et des variables interpolées (propres à chaque fragment), les shaders peuvent recevoir des variables uniformes (uniform) : des valeurs constantes pour l’ensemble des sommets ou fragments d’un même appel de rendu. Elles sont définies côté CPU et envoyées au GPU. Les exemples typiques sont les matrices de transformation, la position de la caméra, la direction de la lumière, le temps courant, etc.
uniform mat4 modelViewProjection; // matrice de transformation (4x4)
uniform vec3 lightDirection; // direction de la lumièreLe pipeline complet fonctionne ainsi :
Les attributs transmis du vertex shader au fragment shader (comme
vertexColor) sont automatiquement
interpolés de manière barycentrique entre les sommets
du triangle, ce qui correspond exactement à l’interpolation
barycentrique décrite précédemment. L’ensemble de ce pipeline est résumé
sur le schéma ci-dessous.

Comme vu au chapitre précédent, une scène 3D est décrite par des modèles (surfaces), des sources de lumière et une caméra. Le rendu par rasterization produit une image 2D de cette scène.
Cependant, au niveau du GPU et d’OpenGL, il n’existe pas de notion explicite de caméra ni de lumière. Le GPU ne manipule que des sommets avec leurs attributs (position, couleur, normale, etc.) en entrée du vertex shader, et des fragments (pixels) colorés en sortie du fragment shader. Tout le travail du programmeur consiste à traduire les concepts de haut niveau (caméra, lumière, matériaux) en opérations sur les sommets et les fragments via les shaders.
Le pipeline de rendu se décompose en trois grandes étapes. La première est la transformation des sommets, réalisée par le vertex shader : chaque sommet est projeté depuis l’espace 3D de la scène vers l’espace 2D de l’écran en appliquant les matrices de transformation et de projection. La deuxième étape est la rasterization : les triangles projetés en 2D sont convertis en fragments (pixels) par un processus de discrétisation automatique. Enfin, la troisième étape est le calcul de la couleur, effectué par le fragment shader : pour chaque fragment, on détermine sa couleur finale en fonction de l’éclairage, du matériau et des textures.
OpenGL n’affiche que les triangles dont les sommets se trouvent dans le cube \([-1, 1]^3\). Cet espace normalisé est appelé Normalized Device Coordinates (NDC). Les deux premières composantes \((x_{\text{ndc}}, y_{\text{ndc}})\) correspondent aux coordonnées écran, tandis que \(z_{\text{ndc}}\) encode la profondeur, c’est-à-dire la distance à la caméra dans l’espace image. Ce cube normalisé est représenté sur la figure suivante.

L’objectif de la projection est de convertir les coordonnées globales (world space) en coordonnées NDC. Cette conversion doit d’une part définir un modèle de caméra qui spécifie quelle partie de l’espace 3D est visible, et d’autre part appliquer la perspective pour que les objets éloignés apparaissent plus petits que les objets proches.
Le modèle de perspective le plus courant utilise un volume de visibilité en forme de tronc de pyramide (frustum), délimité par un plan proche (\(z_{\text{near}}\)) et un plan lointain (\(z_{\text{far}}\)), comme illustré ci-dessous.

Soit un point de coordonnées \((x, y, z)\) dans l’espace monde. Les coordonnées NDC \((x_{\text{ndc}}, y_{\text{ndc}}, z_{\text{ndc}})\) sont calculées comme suit :
Coordonnées \(x\) et \(y\) :
\[ x_{\text{ndc}} = \frac{z_{\text{near}}}{-z} \cdot \frac{x}{w} = \frac{1}{\tan(\theta/2)} \cdot \frac{x}{-z} \]
\[ y_{\text{ndc}} = \frac{z_{\text{near}}}{-z} \cdot \frac{y}{h} = \frac{r}{\tan(\theta/2)} \cdot \frac{y}{-z} \]
où \(\theta\) est le champ de vision (Field of View, FOV) et \(r = h/w\) est le ratio d’aspect.
La division par \(-z\) produit l’effet de perspective : les objets éloignés (grand \(|z|\)) sont réduits en taille.
Coordonnée \(z\) (profondeur) :
La profondeur NDC est une fonction non linéaire de \(z\) :
\[ z_{\text{ndc}} = \frac{1}{-z} \left( -\frac{z_{\text{far}} + z_{\text{near}}}{z_{\text{far}} - z_{\text{near}}} \cdot z - \frac{2 \, z_{\text{near}} \, z_{\text{far}}}{z_{\text{far}} - z_{\text{near}}} \right) \]
avec les correspondances : \(z = -z_{\text{near}} \rightarrow z_{\text{ndc}} = -1\) et \(z = -z_{\text{far}} \rightarrow z_{\text{ndc}} = 1\).
La variation en \(1/z\) implique une précision plus fine près de la caméra et plus grossière au loin. C’est un choix délibéré : les objets proches nécessitent une meilleure résolution en profondeur pour éviter les artefacts visuels.
En coordonnées homogènes, la projection s’exprime comme un produit matriciel \(4 \times 4\) :
\[ p_{\text{ndc}} = \text{Proj} \times p \]
avec :
\[ \text{Proj} = \begin{pmatrix} \frac{1}{\tan(\theta/2)} & 0 & 0 & 0 \\ 0 & \frac{r}{\tan(\theta/2)} & 0 & 0 \\ 0 & 0 & -\frac{z_{\text{far}} + z_{\text{near}}}{z_{\text{far}} - z_{\text{near}}} & -\frac{2 \, z_{\text{near}} \, z_{\text{far}}}{z_{\text{far}} - z_{\text{near}}} \\ 0 & 0 & -1 & 0 \end{pmatrix} \]
Après multiplication, le vecteur obtenu a une composante \(w \neq 1\). L’homogénéisation (division par \(w\)) produit les coordonnées NDC finales. C’est exactement le mécanisme de l’espace projectif vu au chapitre précédent.
Le résultat est un espace déformé dans le cube \([-1, 1]^3\). L’image finale correspond à la vue \((x_{\text{ndc}}, y_{\text{ndc}})\) de ce cube, tandis que \(z_{\text{ndc}}\) représente la profondeur vue depuis la caméra dans l’espace image. Tout ce qui se trouve en dehors du cube \([-1, 1]^3\) est automatiquement écarté par le GPU (clipping).
La variation en \(1/z\) de la profondeur NDC a une conséquence importante : la précision dépend fortement du choix de \(z_{\text{near}}\). Le schéma suivant montre cette distribution non uniforme de la précision.

Si \(z_{\text{near}}\) est trop proche de 0, toute la précision est concentrée sur les distances très proches de la caméra. Les objets éloignés se retrouvent avec des valeurs de profondeur presque identiques après discrétisation. Cela provoque un artefact visuel appelé z-fighting (ou depth-fighting) : deux surfaces proches en profondeur “clignotent” de manière aléatoire car le GPU ne peut pas déterminer laquelle est devant. Le graphique ci-dessous illustre la courbe de \(z_{\text{ndc}}\) en fonction de \(z\).
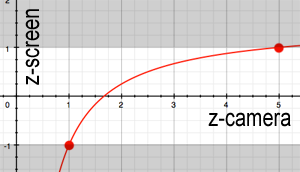
Règle pratique : choisir \(z_{\text{near}}\) aussi grand que possible (tout en gardant les objets visibles dans le frustum) pour maximiser la précision en profondeur sur toute la scène.
La matrice de vue transforme les coordonnées de l’espace monde vers l’espace caméra (view space). Elle positionne et oriente la caméra dans la scène, selon le principe illustré ci-dessous.

La caméra est décrite par une matrice \(4 \times 4\) contenant ses axes locaux et sa position :
\[ \text{Cam} = \begin{pmatrix} \text{right}_x & \text{up}_x & \text{back}_x & \text{eye}_x \\ \text{right}_y & \text{up}_y & \text{back}_y & \text{eye}_y \\ \text{right}_z & \text{up}_z & \text{back}_z & \text{eye}_z \\ 0 & 0 & 0 & 1 \end{pmatrix} = \begin{pmatrix} O & \text{eye} \\ 0 & 1 \end{pmatrix} \]
où \(O = (\text{right}, \text{up}, \text{back})\) est la matrice de rotation de la caméra (base orthonormée) et \(\text{eye}\) est sa position dans le monde.
La matrice de vue est l’inverse de la matrice caméra :
\[ \text{View} = \text{Cam}^{-1} = \begin{pmatrix} O^T & -O^T \cdot \text{eye} \\ 0 & 1 \end{pmatrix} \]
Cette inversion est très efficace à calculer car \(O\) est orthogonale (\(O^{-1} = O^T\)). La matrice de vue envoie la position de la caméra sur l’origine et aligne ses axes sur les axes du repère.
La matrice de modèle positionne un objet dans le monde. Elle transforme les coordonnées locales de l’objet vers les coordonnées de l’espace monde :
\[ \text{Model} = \begin{pmatrix} R & t \\ 0 & 1 \end{pmatrix} \]
où \(R\) est la matrice de rotation (orientation de l’objet) et \(t\) est le vecteur de translation (position de l’objet). La figure suivante montre ce passage des coordonnées locales à l’espace monde.

L’intérêt de séparer la géométrie de l’objet de sa position est fondamental. Les coordonnées géométriques de l’objet (maillage) sont chargées une seule fois en VRAM, et pour déplacer ou orienter l’objet, il suffit de modifier la matrice Model, soit une simple matrice \(4 \times 4\) de 16 flottants. Cette séparation permet également l’instanciation : le même maillage peut être affiché à plusieurs endroits de la scène en appliquant des matrices Model différentes, sans dupliquer les données géométriques en mémoire. Par exemple, une forêt composée de milliers d’arbres peut ne stocker qu’un seul maillage d’arbre, chaque instance ayant sa propre matrice Model (position, rotation, échelle).
La transformation complète d’un sommet, depuis ses coordonnées locales jusqu’à l’espace NDC, est la composition des trois matrices :
\[ p_{\text{ndc}} = \text{Proj} \times \text{View} \times \text{Model} \times p \]
Le sommet part de ses coordonnées locales \(p = (x, y, z, 1)\) dans l’espace objet, où la géométrie est définie relativement à l’origine de l’objet. La matrice Model le place dans l’espace monde : \(p_{\text{world}} = \text{Model} \times p\), en appliquant la rotation, l’échelle et la translation de l’objet. La matrice View transforme ensuite cette position dans l’espace caméra : \(p_{\text{view}} = \text{View} \times p_{\text{world}}\), où la caméra se trouve à l’origine et regarde dans la direction \(-z\). Enfin, la matrice de Projection convertit les coordonnées en NDC : \(p_{\text{ndc}} = \text{Proj} \times p_{\text{view}}\), en appliquant la perspective et en normalisant les coordonnées dans le cube \([-1, 1]^3\) après homogénéisation (division par \(w\)).
Cette chaîne constitue la première étape du pipeline graphique, réalisée par le vertex shader.
#version 330 core
layout (location = 0) in vec3 vertex_position;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
void main() {
gl_Position = projection * view * model * vec4(vertex_position, 1.0);
}Les trois matrices sont envoyées au GPU comme variables uniformes depuis le code C++. Le GPU applique ensuite cette transformation en parallèle sur tous les sommets. Cela est bien plus efficace que de calculer les nouvelles positions sur le CPU : au lieu de transférer \(N\) positions modifiées à chaque image, on ne transfère que trois matrices \(4 \times 4\) (soit 48 flottants).
void main_loop() {
// Mise à jour des matrices
glUniform(shader, Model);
glUniform(shader, View);
glUniform(shader, Projection);
draw(mesh_drawable);
}La rasterization (ou rastérisation, ou facétisation) est la conversion de données vectorielles (triangles définis par des sommets) en éléments discrets : des pixels (ou fragments). C’est une étape automatique et non programmable dans le pipeline OpenGL.
L’opération fondamentale est la suivante : étant donné un triangle défini par 3 points 2D (après projection), déterminer l’ensemble des pixels qu’il recouvre, comme on peut le voir sur la figure suivante.

Avant d’aborder la rasterization des triangles, considérons des primitives plus simples pour comprendre le principe de discrétisation.
Point : un seul pixel.
im(x0, y0) = c;Rectangle : deux boucles imbriquées.
for(int kx = x0; kx < x1; kx++)
for(int ky = y0; ky < y1; ky++)
im(kx, ky) = c;Segment horizontal, vertical ou diagonal : une seule boucle suffit.
// Segment horizontal
for(int kx = x0; kx < x1; kx++)
im(kx, y0) = c;Pour un segment quelconque, la discrétisation n’est plus triviale : plusieurs approximations pixelisées sont possibles, comme le montre l’image ci-dessous. Il faut choisir un algorithme efficace et déterministe.
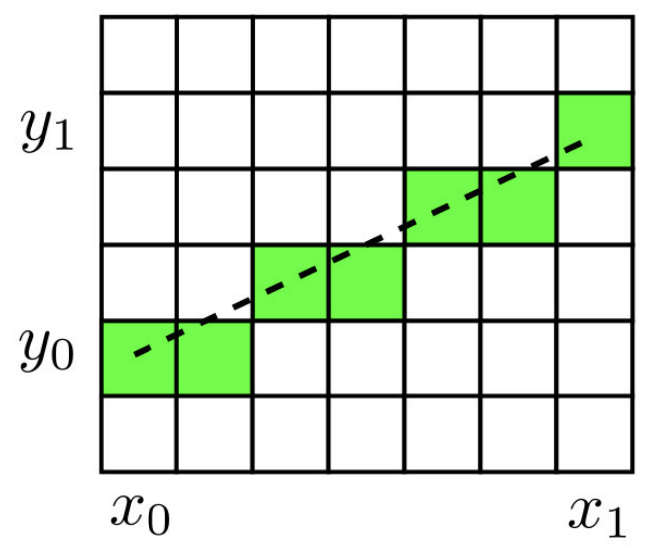
L’algorithme de Bresenham est un algorithme classique et très efficace pour rasteriser un segment. Il repose uniquement sur des opérations entières, ce qui le rend rapide et exact.
Principe : on avance le long de l’axe \(x\) pixel par pixel. À chaque pas, on évalue si l’erreur accumulée en \(y\) dépasse \(0.5\) :
La progression de l’algorithme est visualisée sur la figure suivante.

int dx = x1 - x0, dy = y1 - y0;
float a = float(dy) / float(dx);
float erreur = 0.0f;
int y = y0;
for(int x = x0; x <= x1; x++)
{
im(x, y) = c;
erreur += a;
if(erreur >= 0.5f)
{
y = y + 1;
erreur = erreur - 1.0f;
}
}Remarque : en multipliant toutes les valeurs par \(2 \, dx\), on peut éliminer les divisions et les flottants pour obtenir un algorithme purement entier. L’algorithme ci-dessus traite le cas \(0 \leq dy \leq dx\) ; les autres octants se traitent par symétrie.
La rasterization d’un triangle \((p_0, p_1, p_2)\) se fait par l’algorithme scanline :
Discrétiser les arêtes : pour chaque arête du triangle (\((p_0, p_1)\), \((p_1, p_2)\), \((p_2, p_0)\)), appliquer l’algorithme de Bresenham pour obtenir les pixels de contour.
Stocker les bornes horizontales : pour chaque ligne \(y\), stocker les valeurs \(x_{\min}\) et \(x_{\max}\) des pixels de contour.
Remplir ligne par ligne : pour chaque ligne \(y\), colorier tous les pixels de \(x_{\min}\) à \(x_{\max}\).
Les deux étapes sont illustrées ci-dessous : discrétisation des arêtes puis remplissage.


Rasterization d'un triangle par scanline : discrétisation des arêtes (gauche) et remplissage horizontal (droite).
Exemple de table scanline pour un triangle :
| \(y\) | \(x_{\min}\) | \(x_{\max}\) |
|---|---|---|
| 0 | 3 | 5 |
| 1 | 0 | 5 |
| 2 | 1 | 4 |
| 3 | 2 | 4 |
| 4 | 3 | 3 |
Lors du remplissage, les coordonnées barycentriques de chaque fragment sont calculées pour interpoler les attributs des sommets (couleur, normale, coordonnées de texture, profondeur) de manière linéaire à l’intérieur du triangle.
Le modèle de Phong est le modèle d’illumination le plus classique en rendu temps réel. Il repose sur l’observation que l’apparence d’une surface éclairée peut être décomposée en trois phénomènes physiques distincts. Le premier est la composante ambiante, qui représente une couleur de base uniforme, indépendante de la géométrie et de la position de la lumière : elle modélise de manière grossière la lumière indirecte qui baigne l’ensemble de la scène. Le deuxième est la composante diffuse, qui dépend de l’orientation locale de la surface par rapport à la lumière : une surface tournée vers la lumière est claire, une surface tournée dans l’autre sens est sombre. Le troisième est la composante spéculaire, qui modélise le reflet brillant de la source lumineuse visible sur les surfaces lisses, et qui dépend du point de vue de l’observateur. Ces trois contributions sont représentées sur la figure suivante.

La couleur finale d’un point est la somme de ces trois composantes :
\[ C = C_a + C_d + C_s \]
Le calcul de chaque composante fait intervenir deux propriétés de couleur : la couleur de la source lumineuse \(C_\ell = (r_\ell, g_\ell, b_\ell) \in [0, 1]^3\) et la couleur de la surface (ou albedo) \(C_o = (r_o, g_o, b_o) \in [0, 1]^3\). Leur multiplication composante par composante (\((r_\ell \cdot r_o, \, g_\ell \cdot g_o, \, b_\ell \cdot b_o)\)) modélise le filtrage de la lumière par le matériau : une surface rouge éclairée par une lumière blanche apparaît rouge, tandis que la même surface éclairée par une lumière verte apparaît noire (car la composante rouge de la lumière est nulle).
La composante ambiante modélise une illumination uniforme de la scène (lumière indirecte approximée). Elle ne dépend ni de la position ni de l’orientation de la surface :
\[ C_a = \alpha_a \, C_\ell \, C_o \]
avec \(\alpha_a \in [0, 1]\) le coefficient ambiant. Ce terme évite que les surfaces non éclairées directement soient complètement noires.
La composante diffuse modélise la lumière réfléchie de manière uniforme dans toutes les directions par une surface mate (réflexion lambertienne). Elle dépend de l’angle entre la normale \(n\) à la surface et la direction de la lumière \(u_\ell\) :
\[ C_d = \alpha_d \, (n \cdot u_\ell)_+ \, C_\ell \, C_o \]
Le coefficient \(\alpha_d \in [0, 1]\) contrôle l’intensité de la réflexion diffuse du matériau. Le terme central est le facteur diffus \((n \cdot u_\ell)_+ = \max(n \cdot u_\ell, \, 0)\), qui est le produit scalaire entre le vecteur normal unitaire \(n\) à la surface et la direction unitaire \(u_\ell\) du point vers la source lumineuse. Ce produit scalaire mesure le cosinus de l’angle entre la normale et la direction de la lumière. Lorsque la surface fait directement face à la lumière (\(n\) parallèle à \(u_\ell\)), le facteur vaut 1 et l’éclairage est maximal. Lorsque la surface est rasante (\(n\) perpendiculaire à \(u_\ell\)), le facteur vaut 0. Lorsque la surface est tournée à l’opposé de la lumière, le produit scalaire est négatif, et la troncature \(\max(\cdot, 0)\) force la contribution à zéro, évitant un éclairage physiquement absurde.
Ce mécanisme géométrique est schématisé ci-dessous.

La composante spéculaire modélise le reflet de la source lumineuse sur la surface. Contrairement à la composante diffuse, elle dépend du point de vue de la caméra :
\[ C_s = \alpha_s \, (u_r \cdot u_v)_+^{s_{\exp}} \, C_\ell \]
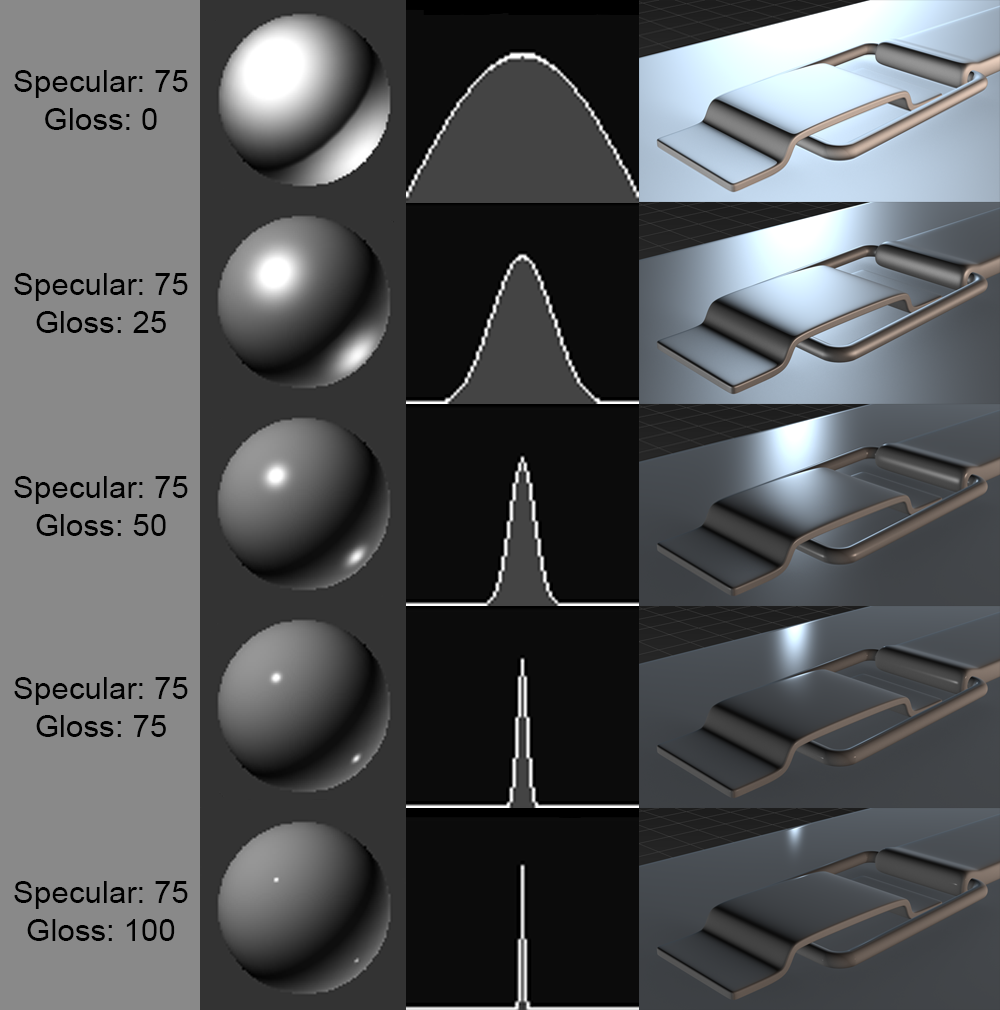
Le coefficient \(\alpha_s \in [0, 1]\) contrôle l’intensité du reflet. L’exposant de brillance \(s_{\exp}\) (typiquement entre 64 et 256) détermine la taille du reflet : plus il est élevé, plus le reflet est concentré en un point étroit et net (surface très polie), tandis qu’un exposant faible produit un reflet large et diffus (surface légèrement rugueuse).
Le vecteur \(u_r\) est la
direction de réflexion de la lumière par rapport à la
normale, calculée par la formule \(u_r = 2 \,
(u_\ell \cdot n) \, n - u_\ell\) (en GLSL :
reflect(-u_l, n)). Le vecteur \(u_v\) est la direction unitaire du point de
la surface vers la caméra. Le produit scalaire \((u_r \cdot u_v)\) mesure l’alignement entre
la direction de réflexion et la direction de vue : le reflet est maximal
lorsque l’observateur se trouve exactement dans la direction de
réflexion miroir de la lumière.
La composante spéculaire ne dépend pas de la couleur de la surface \(C_o\) mais uniquement de \(C_\ell\), ce qui correspond au comportement physique des reflets sur les matériaux diélectriques (plastique, céramique, etc.) : le reflet d’une lumière blanche sur une surface rouge reste blanc. La géométrie de la réflexion spéculaire et l’influence de l’exposant de brillance sont détaillées dans les figures suivantes.

Le modèle de Phong définit la formule d’illumination en un point de la surface, mais reste la question de où et à quelle fréquence cette formule est évaluée. Trois stratégies classiques existent, avec un compromis entre coût de calcul et qualité visuelle.
Le flat shading est l’approche la plus simple : la couleur est calculée une seule fois par triangle, en utilisant la normale géométrique de la face. Tous les pixels du triangle reçoivent exactement la même couleur. Le résultat a un aspect facetté caractéristique où chaque triangle est clairement visible, ce qui peut être acceptable pour du rendu non photo-réaliste mais est inadapté pour des surfaces lisses.
Le Gouraud shading améliore la qualité en calculant l’illumination aux sommets du triangle (dans le vertex shader), puis en interpolant linéairement la couleur résultante à l’intérieur du triangle lors de la rasterization. Les transitions de couleur entre triangles adjacents deviennent douces, donnant une apparence de surface lisse. Cependant, cette approche présente un défaut important : si un reflet spéculaire tombe au milieu d’un grand triangle, loin de tout sommet, il sera complètement manqué car aucun sommet n’a “vu” le reflet.
Le Phong shading résout ce problème en interpolant non pas la couleur, mais la normale entre les sommets du triangle. L’illumination est ensuite calculée pour chaque fragment (dans le fragment shader) avec cette normale interpolée. Le reflet spéculaire est ainsi correctement calculé en chaque point de la surface, même au centre d’un grand triangle. La différence visuelle entre ces trois approches est comparée sur la figure suivante.

En pratique, le Phong shading est le standard. Le surcoût par rapport au Gouraud shading est négligeable sur les GPU modernes (le fragment shader effectue quelques opérations supplémentaires par pixel, mais le GPU dispose de milliers de cœurs pour les exécuter en parallèle), et la qualité visuelle est nettement supérieure.
Le modèle de Phong s’étend naturellement à plusieurs sources lumineuses en sommant les contributions de chaque lumière :
\[ C = \sum_i \left( \alpha_a \, C_{\ell_i} \, C_o + \alpha_d \, (n \cdot u_{\ell_i})_+ \, C_{\ell_i} \, C_o + \alpha_s \, (u_{r_i} \cdot u_v)_+^{s_{\exp}} \, C_{\ell_i} \right) \]
Dans la réalité physique, l’intensité lumineuse d’une source ponctuelle diminue proportionnellement à l’inverse du carré de la distance (\(1/r^2\)). En rendu temps réel, on utilise souvent un modèle d’atténuation simplifié qui décroît linéairement jusqu’à une distance maximale, au-delà de laquelle la lumière n’a plus d’effet :
\[ C_\ell(p) = \left(1 - \min\left(\frac{\|p - p_\ell\|}{d_{\text{att}}}, \, 1\right)\right) \, C_\ell^0 \]
Le vecteur \(p\) est la position du point sur la surface, \(p_\ell\) la position de la lumière, \(d_{\text{att}}\) la distance caractéristique d’atténuation (au-delà de laquelle la contribution est nulle), et \(C_\ell^0\) la couleur de la lumière à la source. Ce modèle linéaire est moins réaliste que la loi en \(1/r^2\), mais il a l’avantage de garantir que la lumière s’éteint complètement au-delà de \(d_{\text{att}}\), ce qui permet d’optimiser le rendu en ignorant les lumières trop éloignées.
Un effet de brouillard simule l’absorption et la diffusion de la lumière par l’atmosphère. Le principe est de mélanger progressivement la couleur calculée avec une couleur de brouillard uniforme en fonction de la distance à la caméra :
\[ C_{\text{final}} = (1 - \gamma(p)) \, C + \gamma(p) \, C_{\text{fog}} \]
Le facteur de mélange \(\gamma(p) = \min\left(\frac{\|p - p_{\text{eye}}\|}{d_{\text{fog}}}, \, 1\right)\) varie de 0 (objet proche, couleur inchangée) à 1 (objet lointain, complètement noyé dans le brouillard). Le paramètre \(d_{\text{fog}}\) contrôle la distance à laquelle le brouillard devient totalement opaque, et \(C_{\text{fog}}\) est la couleur du brouillard (souvent un gris clair ou la couleur du ciel). En pratique, cet effet donne une impression de profondeur atmosphérique et masque naturellement le plan de clipping lointain (\(z_{\text{far}}\)), évitant la disparition brutale des objets à l’horizon.
Le toon shading (ou cel shading) est un effet non photo-réaliste qui donne un aspect dessin animé. Le principe est de discrétiser les valeurs de couleur en paliers :
\[ C_{\text{toon}} = \frac{\text{floor}(C \times N)}{N} \]
où \(N\) est le nombre de paliers souhaités. Ce sous-échantillonnage crée des bandes de couleur discrètes caractéristiques du style cartoon, dont on voit un exemple ci-dessous.
Lorsque plusieurs triangles se chevauchent à l’écran, il faut déterminer lequel est visible pour chaque pixel. Sans mécanisme d’occultation, l’ordre d’affichage des triangles détermine le résultat, ce qui est incorrect, comme le met en évidence l’image suivante.

Le Z-buffer (ou depth buffer) est une image auxiliaire de la même résolution que l’image finale, qui stocke la valeur de profondeur \(z_{\text{ndc}}\) du fragment le plus proche de la caméra pour chaque pixel.
L’algorithme est simple : pour chaque fragment à dessiner, on compare sa profondeur avec la valeur stockée dans le Z-buffer :
def draw(position, couleur, z, image, zbuffer):
if z < zbuffer(position):
image(position) = couleur
zbuffer(position) = z
# sinon: ne rien dessiner (fragment masqué)On peut visualiser le contenu du Z-buffer sous forme d’image en niveaux de gris.

Le Z-buffer est initialisé à la valeur maximale de profondeur (1.0, correspondant au plan lointain) à chaque début de frame. Chaque fragment met à jour le Z-buffer si sa profondeur est inférieure (plus proche de la caméra) à la valeur stockée. Cela garantit que seul le fragment le plus proche est affiché, indépendamment de l’ordre de dessin des triangles.
Cette étape est réalisée automatiquement par le GPU (non
programmable), à condition d’activer le test de profondeur
(glEnable(GL_DEPTH_TEST) en OpenGL).
Le pipeline de rendu complet enchaîne plusieurs étapes en séquence. Le vertex shader transforme d’abord chaque sommet en appliquant la chaîne de matrices Projection \(\times\) View \(\times\) Model, et transmet les attributs transformés (position en espace monde, normale, couleur) vers les étapes suivantes. Les sommets transformés sont ensuite regroupés en triangles lors de l’assemblage des primitives, en utilisant la table de connectivité envoyée depuis le CPU.
La rasterization prend chaque triangle projeté en 2D et détermine l’ensemble des pixels qu’il recouvre. Pour chaque pixel couvert (appelé fragment), les attributs des trois sommets du triangle sont interpolés de manière barycentrique. Le fragment shader reçoit ces attributs interpolés et calcule la couleur finale du fragment en appliquant le modèle d’illumination de Phong. Le test de profondeur (Z-buffer) compare ensuite la profondeur du fragment avec la valeur stockée pour ce pixel : seul le fragment le plus proche de la caméra est conservé, les autres sont écartés. Le résultat de l’ensemble de ces étapes est l’image finale, stockée dans le framebuffer et affichée à l’écran.
L’enchaînement complet de ces étapes est résumé dans le schéma ci-dessous.

Vertex shader : transforme les positions et normales, transmet les attributs au fragment shader.
#version 330 core
layout (location = 0) in vec3 vertex_position;
layout (location = 1) in vec3 vertex_normal;
layout (location = 2) in vec3 vertex_color;
out struct fragment_data {
vec3 position;
vec3 normal;
vec3 color;
} fragment;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
void main() {
vec4 position = model * vec4(vertex_position, 1.0);
mat4 modelNormal = transpose(inverse(model));
vec4 normal = modelNormal * vec4(vertex_normal, 0.0);
fragment.position = position.xyz;
fragment.normal = normal.xyz;
fragment.color = vertex_color;
gl_Position = projection * view * position;
}Remarque : la normale est transformée par la transposée de
l’inverse de la matrice Model
(transpose(inverse(model))), et non par Model directement.
En effet, si Model contient un scaling non uniforme, la multiplication
directe déformerait les normales et l’ombrage serait incorrect.
Fragment shader : calcule l’illumination de Phong pour chaque fragment.
#version 330 core
in struct fragment_data {
vec3 position;
vec3 normal;
vec3 color;
} fragment;
uniform vec3 light_position;
uniform vec3 light_color;
layout(location = 0) out vec4 FragColor;
void main() {
vec3 N = normalize(fragment.normal);
vec3 L = normalize(light_position - fragment.position);
float diffuse_magnitude = max(dot(N, L), 0.0);
vec3 c = 0.1 * fragment.color * light_color; // ambiante
c = c + 0.7 * diffuse_magnitude * fragment.color * light_color; // diffuse
// + composante spéculaire (omise pour simplifier)
FragColor = vec4(c, 1.0);
}Les variables fragment.position,
fragment.normal et fragment.color sont
automatiquement interpolées de manière barycentrique
par le GPU entre les valeurs des trois sommets du triangle courant.
Un maillage (mesh) est un ensemble de polygones partageant des sommets. Il est décrit par :
Selon le type de polygones utilisés, on distingue :
Ces trois catégories sont illustrées ci-dessous.

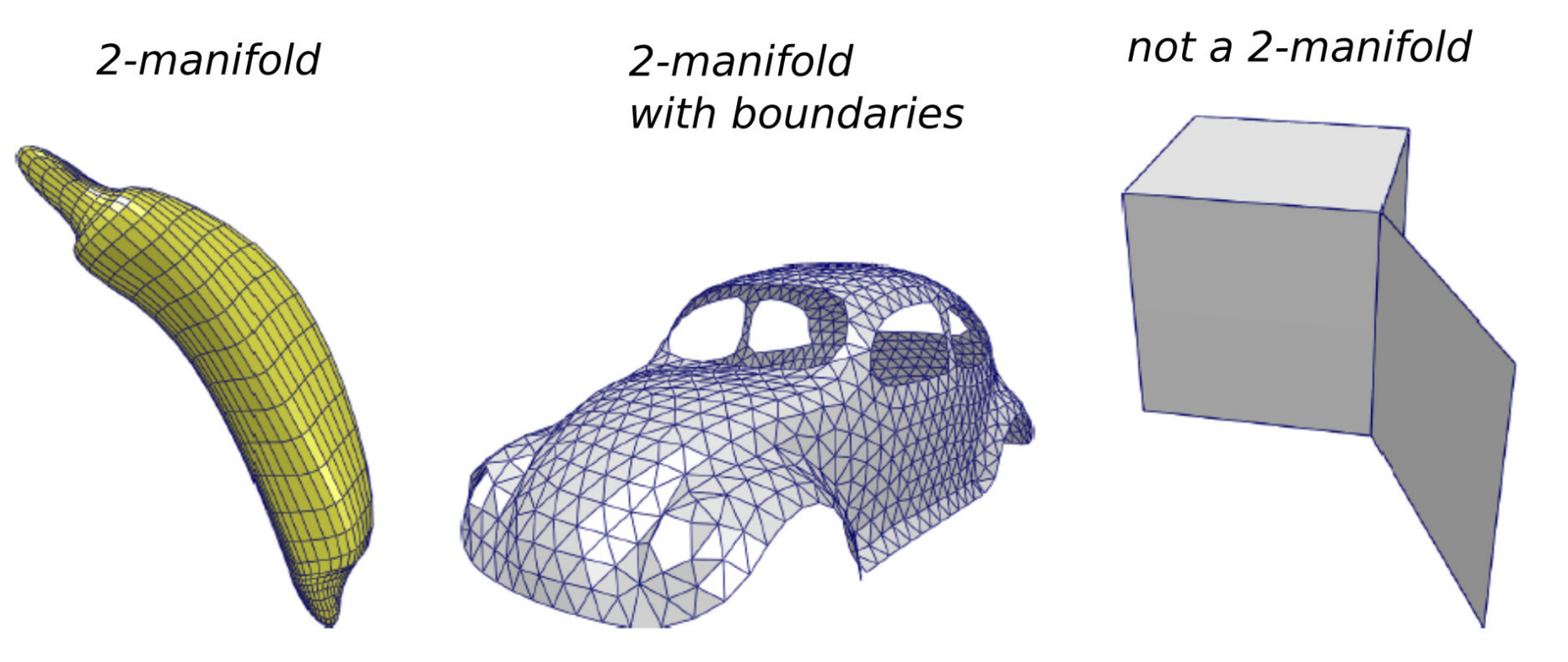
Un maillage représente une variété (manifold) si chaque arête est partagée par au plus 2 faces, comme illustré sur la figure suivante. Cette propriété garantit que la surface est localement équivalente à un plan (ou un demi-plan au bord), ce qui est nécessaire pour la plupart des algorithmes de traitement de maillage.
L’encodage standard d’un maillage triangulaire en C++ utilise deux tableaux :
struct vec3 { float x, y, z; };
struct int3 { int i, j, k; };
std::vector<vec3> position; // positions des sommets
std::vector<int3> connectivity; // indices des faces (triplets)L’utilisation de std::vector garantit la
contiguïté mémoire, essentielle pour le transfert
efficace vers le GPU.
Exemple : tétraèdre
std::vector<vec3> position = { {0,0,0}, {1,0,0}, {0,1,0}, {0,0,1} };
std::vector<int3> connectivity = { {0,1,2}, {0,1,3}, {0,2,3}, {1,2,3} };Exemple : maillage plan
std::vector<vec3> position = { p0, p1, p2, p3, p4, p5, p6, p7, p8 };
std::vector<int3> connectivity = { {0,1,3}, {1,2,3}, {0,3,4}, {3,5,4},
{2,5,3}, {2,6,5}, {5,6,7}, {5,7,8}, {4,5,8} };Le schéma suivant montre la correspondance entre les indices et la géométrie du maillage.

Remarque sur l’orientation : les triplets \((0, 1, 3)\), \((1, 3, 0)\) et \((3, 0, 1)\) sont équivalents (permutation cyclique). En revanche, \((0, 1, 3)\) a une orientation inverse à \((3, 1, 0)\), \((1, 0, 3)\) ou \((0, 3, 1)\). L’orientation détermine la direction de la normale et donc le sens de la face (voir chapitre précédent).
Le flux de travail typique pour afficher un maillage avec OpenGL suit les étapes suivantes :
mesh_drawable
(partagée entre les méthodes).mesh
contenant les tableaux de données en RAM (CPU).mesh vers le
mesh_drawable en VRAM (GPU).draw() qui active le shader, envoie les
uniformes et lance le rendu.Ce flux est résumé dans le diagramme ci-dessous.

En pratique, chaque sommet porte des attributs supplémentaires en plus de sa position : normales, coordonnées de texture, couleurs, etc.
std::vector<vec3> position = { p_0, p_1, p_2, p_3 };
std::vector<vec3> normal = { n_0, n_1, n_2, n_3 };
std::vector<vec3> color = { c_0, c_1, c_2, c_3 };
std::vector<vec2> uv = { uv_0, uv_1, uv_2, uv_3 };
std::vector<int3> connectivity = { {0,1,2}, {0,1,3}, {0,2,3}, {1,2,3} };avec \(p_i = (x_i, y_i, z_i)\), \(n_i = (n_{x_i}, n_{y_i}, n_{z_i})\) avec \(\|n_i\| = 1\), et \(c_i = (r_i, g_i, b_i)\). La figure ci-après représente ces différents attributs sur un maillage.

Points importants :
Parfois, il est nécessaire de dupliquer un sommet lorsqu’il occupe la même position mais avec des attributs différents selon la face considérée. Le cas le plus courant est celui des arêtes vives (sharp edges).
Considérons un sommet situé à une position \(p_A\) où deux groupes de faces se rencontrent à angle droit. Si l’on souhaite un rendu avec une arête nette (non lissée), il faut que ce sommet porte deux normales différentes, une pour chaque groupe de faces. Comme la table de connectivité est unique, on doit créer deux entrées distinctes dans le tableau de sommets, partageant la même position mais avec des normales différentes.
// Avant duplication : sommet v4 à la position pA avec une seule normale
std::vector<vec3> position = { p0, p1, p2, p3, pA, pB };
std::vector<vec3> normal = { n0, n0, n1, n1, n2, n2 };
// Après duplication : v4 et v6 partagent pA mais avec des normales différentes
std::vector<vec3> position = { p0, p1, p2, p3, pA, pB, pA, pB };
std::vector<vec3> normal = { n0, n0, n1, n1, n1, n1, n0, n0 };Le principe est visible sur le schéma suivant.

Pour un cube, chaque sommet géométrique est partagé par 3 faces perpendiculaires. Comme chaque face nécessite une normale différente, chaque sommet est dupliqué 3 fois, soit \(8 \times 3 = 24\) sommets au lieu de 8.
Un cas fréquent de maillage est la discrétisation de surfaces paramétriques.
Soit une surface \(S(u, v) = (S_x(u,v), \, S_y(u,v), \, S_z(u,v))\) avec \((u, v) \in [0, 1]^2\), échantillonnée uniformément sur une grille \(N_u \times N_v\), dont la structure est représentée ci-dessous.

La construction du maillage se fait en deux étapes :
Positions des sommets :
for(int ku = 0; ku < Nu; ku++) {
for(int kv = 0; kv < Nv; kv++) {
float u = ku / (Nu - 1.0f);
float v = kv / (Nv - 1.0f);
S.position[kv + Nv * ku] = { Sx(u,v), Sy(u,v), Sz(u,v) };
}
}Connectivité (deux triangles par cellule de la grille) :
for(int ku = 0; ku < Nu - 1; ku++) {
for(int kv = 0; kv < Nv - 1; kv++) {
unsigned int idx = kv + Nv * ku;
uint3 triangle_1 = { idx, idx + 1 + Nv, idx + 1 };
uint3 triangle_2 = { idx, idx + Nv, idx + 1 + Nv };
S.connectivity.push_back(triangle_1);
S.connectivity.push_back(triangle_2);
}
}Ce schéma s’applique à de nombreuses surfaces, comme le montrent les exemples suivants.
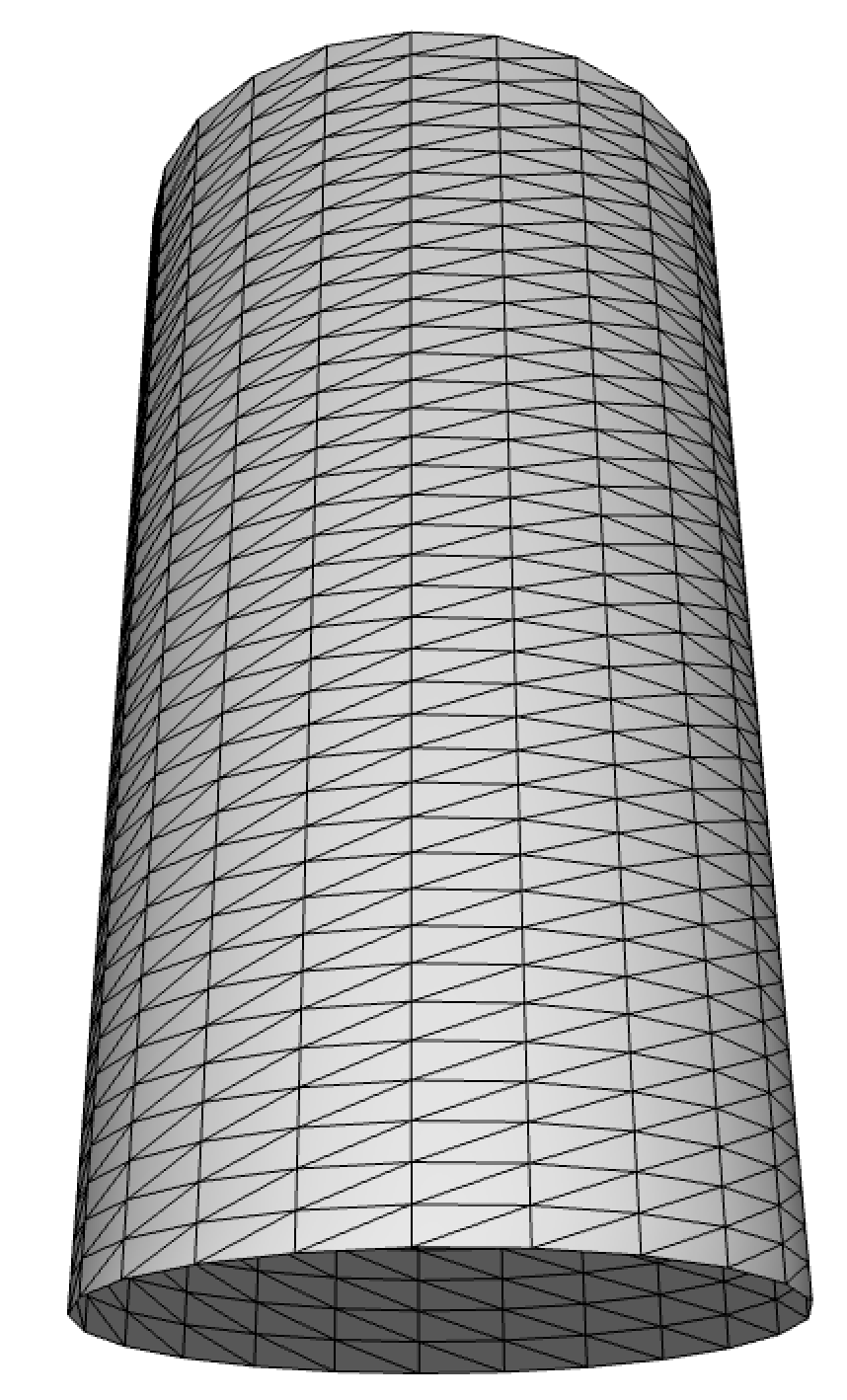

Exemples de surfaces paramétriques : cylindre (gauche) et terrain (droite).
Les normales ne sont pas toujours fournies (fichiers sans normales, maillages procéduraux, déformations en temps réel). Il est alors nécessaire de les calculer à partir de la géométrie.
La méthode standard consiste à calculer la moyenne non pondérée des normales des triangles voisins de chaque sommet :
\[ n_i = \frac{\sum_{t \in \mathcal{N}_i} n_t}{\left\| \sum_{t \in \mathcal{N}_i} n_t \right\|} \]
Ce procédé est illustré ci-dessous.

Implémentation :
std::vector<vec3> normal(position.size(), {0,0,0});
// Accumulation par triangle
for(int t = 0; t < connectivity.size(); t++) {
int a = connectivity[t][0];
int b = connectivity[t][1];
int c = connectivity[t][2];
vec3 n = cross(position[b] - position[a], position[c] - position[a]);
n = normalize(n);
normal[a] += n;
normal[b] += n;
normal[c] += n;
}
// Normalisation finale
for(int k = 0; k < normal.size(); k++) {
normal[k] = normalize(normal[k]);
}Si des sommets sont dupliqués (arêtes vives), les normales calculées seront naturellement différentes pour chaque copie, car elles ne partagent pas les mêmes triangles voisins, comme on peut le voir sur la figure suivante.

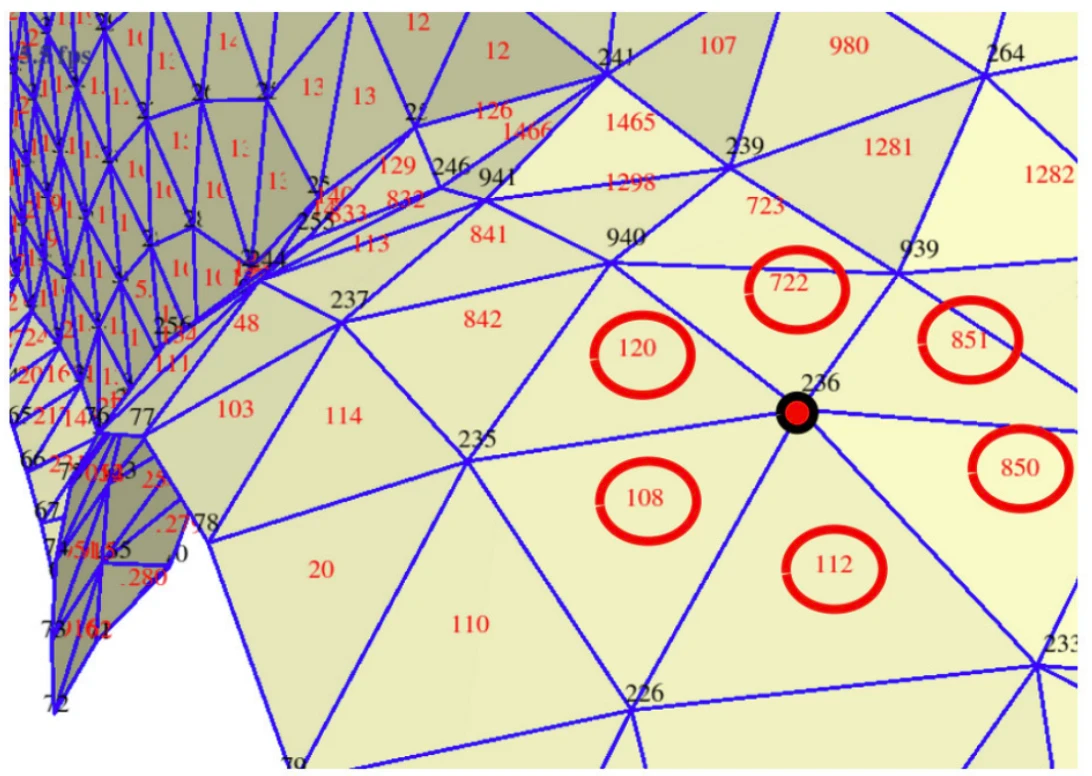
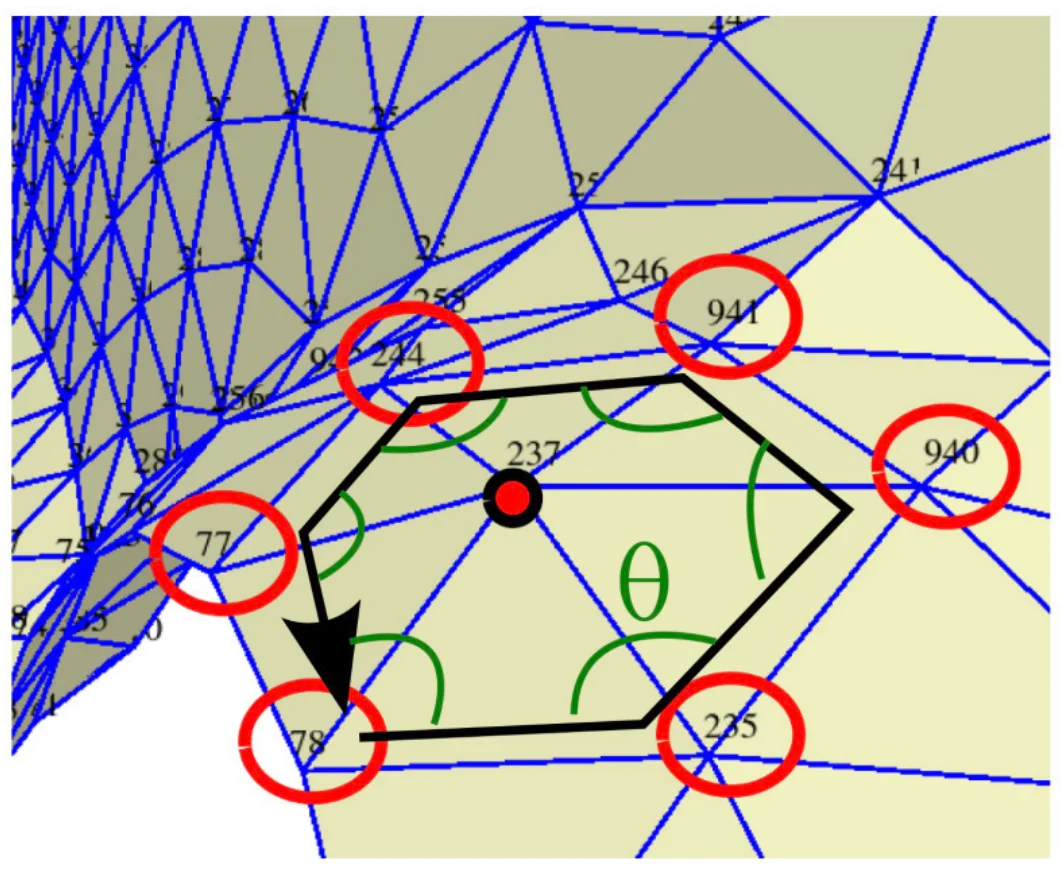
Le 1-ring d’un sommet est l’ensemble des triangles qui partagent ce sommet. Cette structure de voisinage est utile pour de nombreux algorithmes (calcul de normales, lissage, subdivision, etc.).
std::vector<std::vector<int>> one_ring;
one_ring.resize(position.size());
for(int k_tri = 0; k_tri < connectivity.size(); k_tri++) {
for(int k = 0; k < 3; k++) {
one_ring[connectivity[k_tri][k]].push_back(k_tri);
}
}Par exemple :
one_ring[235] = {842, 120, 108, 110, 20, 114};
one_ring[236] = {108, 112, 851, 850, 120, 722};La figure ci-dessous visualise cette notion de voisinage.
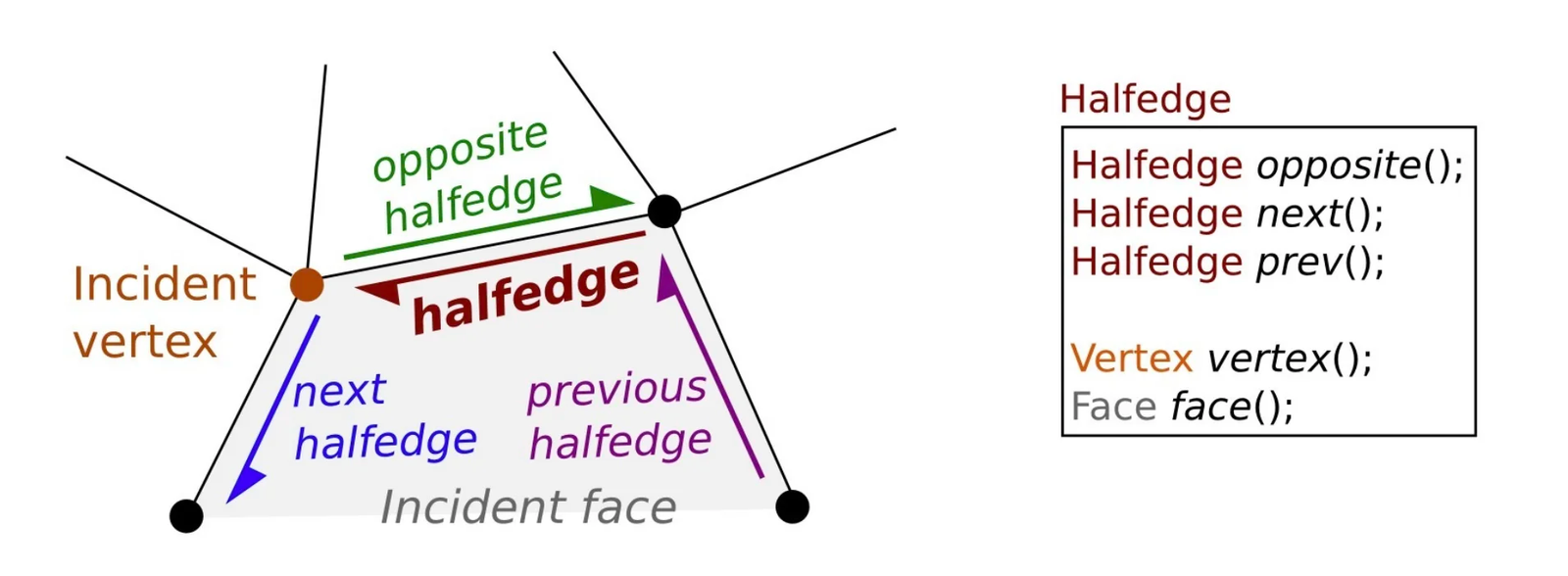
La structure en demi-arête (half-edge) est une structure de données plus riche que la simple table de connectivité. Elle encode les arêtes de manière orientée : chaque arête est représentée par deux demi-arêtes de directions opposées, comme le montre le schéma ci-après. Les faces apparaissent comme des boucles le long des demi-arêtes.
Avantages :
Limitations :
Exemple avec CGAL :
typedef CGAL::Cartesian<double> Kernel;
typedef CGAL::Polyhedron_3<Kernel> Polyhedron;
int main() {
Polyhedron mesh;
std::ifstream stream("mesh.off");
stream >> mesh;
int face_number = 0;
for(auto it_face = mesh.facets_begin();
it_face != mesh.facets_end(); ++it_face)
{
auto halfedge = it_face->halfedge();
auto const halfedge_end = halfedge;
do {
const auto p = halfedge->vertex()->point();
std::cout << p << std::endl;
halfedge = halfedge->next();
} while(halfedge != halfedge_end);
face_number++;
}
}L’objectif des textures est de fournir un niveau de détail en couleur plus fin que la géométrie. Un triangle peut avoir une couleur uniforme ou interpolée entre ses sommets, mais cela reste limité. Les textures permettent de plaquer une image 2D détaillée sur la surface 3D.
Le cas classique est l’UV-mapping : une image 2D (la texture) est associée à la surface 3D via des coordonnées de texture \((u, v)\) (aussi notées \((s, t)\)).
Le mécanisme est illustré ci-dessous.
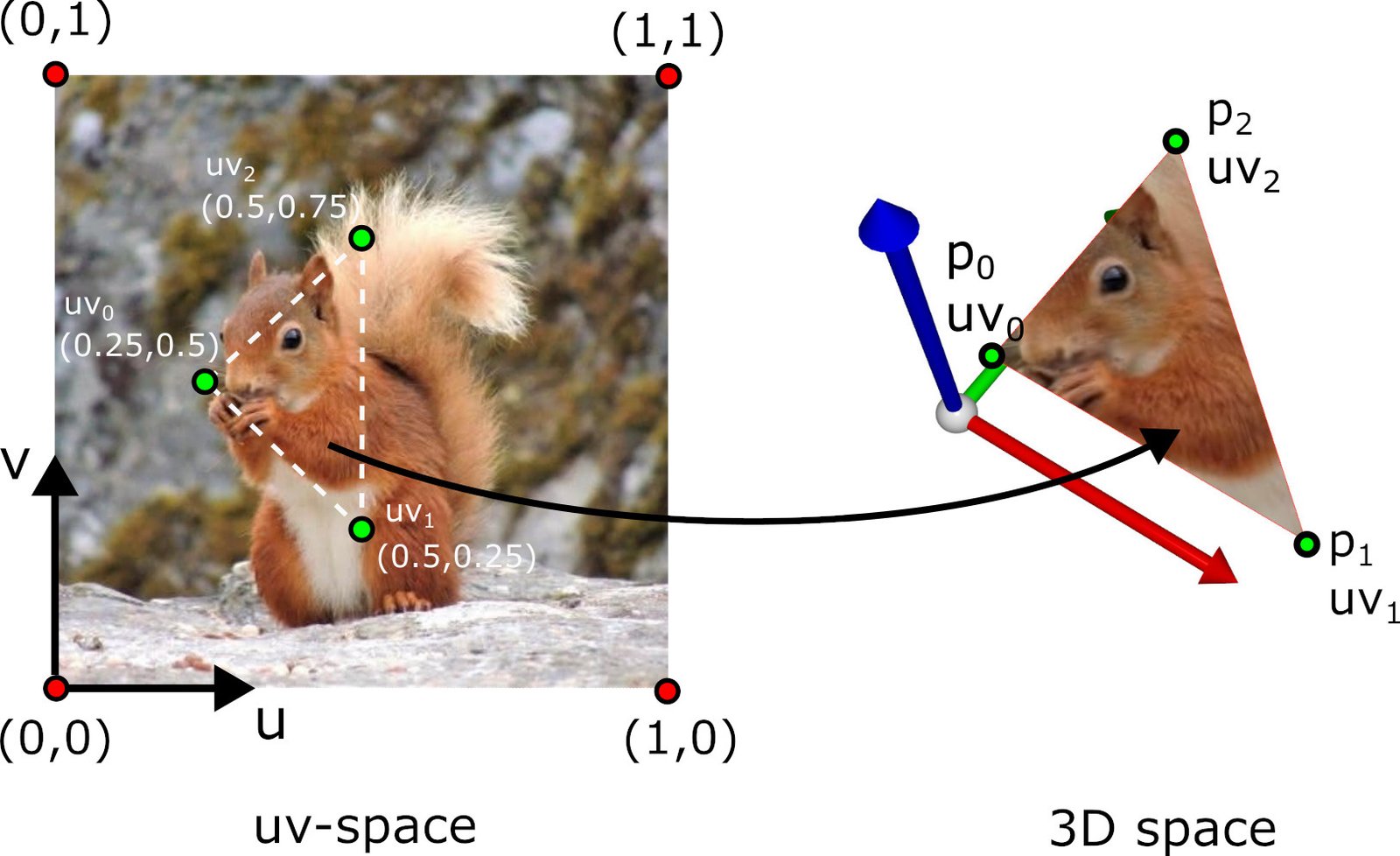
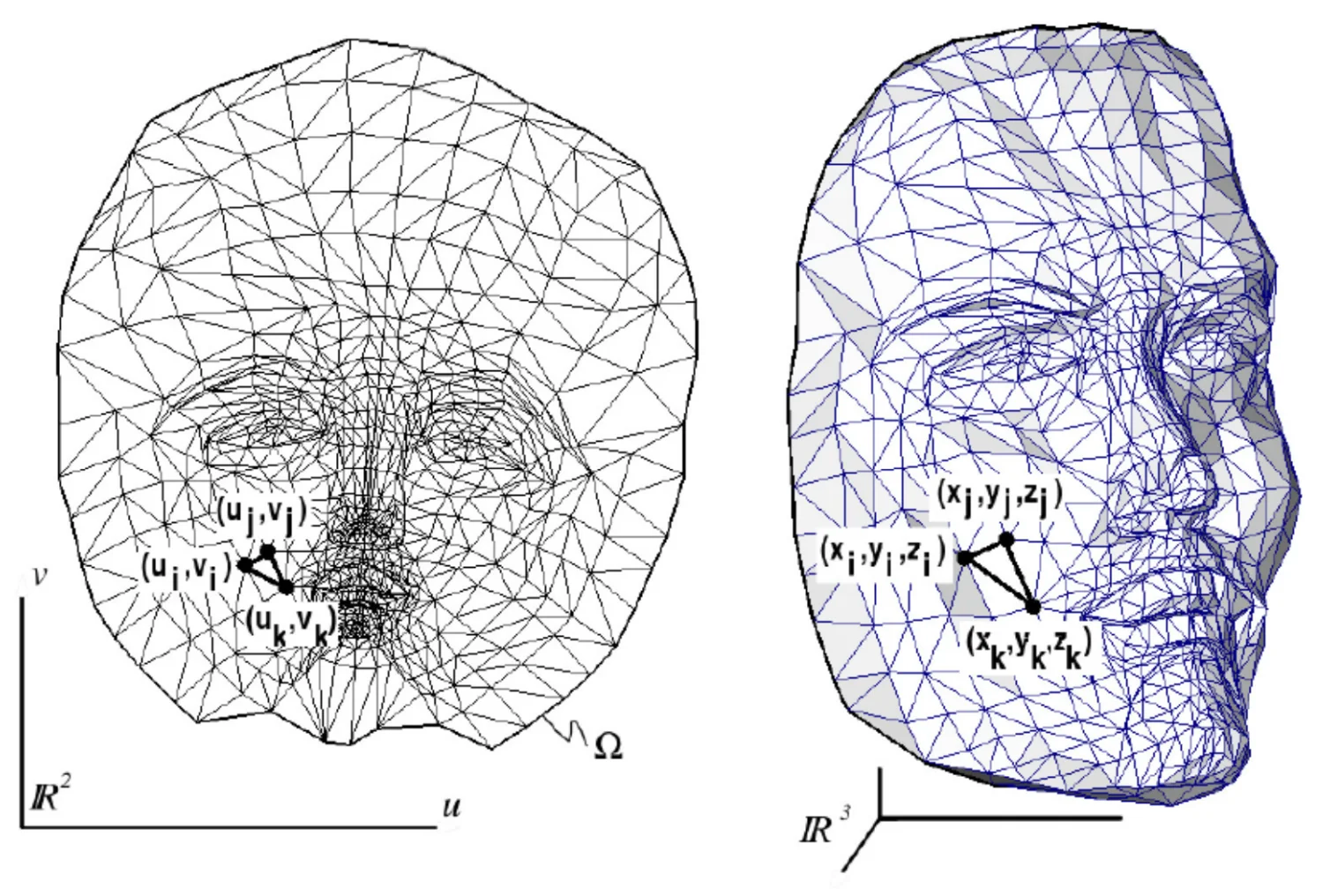
Principe de l'UV-mapping : association entre coordonnées 2D de la texture et surface 3D.
La convention est que \((0, 0)\) correspond au coin inférieur gauche de l’image et \((1, 1)\) au coin supérieur droit.
Pour des modèles complexes, le dépliage UV se fait par morceaux (patches ou îlots). Le processus comprend les étapes suivantes :
Découpage en patches : la surface est découpée le long de coutures (seams) choisies par l’artiste ou un algorithme automatique. Les coutures sont placées dans des zones peu visibles (plis, arrière de l’objet).
Dépliage : chaque patch est déplié dans le plan 2D en minimisant les déformations. Des algorithmes classiques incluent ABF (Angle-Based Flattening), LSCM (Least Squares Conformal Maps) et Slim (Scalable Locally Injective Mappings).
Packing : les patches dépliés sont disposés dans l’espace \([0, 1]^2\) en maximisant l’occupation de l’espace (pour éviter de gaspiller la résolution de texture).
Peinture : l’artiste peint la texture directement dans l’espace 2D déplié, ou utilise des outils de peinture 3D (comme Substance Painter) qui projettent directement sur la surface.
Les coutures entre les patches correspondent aux endroits où la texture peut présenter des discontinuités (le sommet à la couture est dupliqué avec des coordonnées UV différentes de chaque côté). Un exemple de dépliage est visible ci-dessous.

L’UV-mapping consiste à “déplier” la surface 3D sur un plan 2D. Ce dépliage introduit nécessairement des déformations en longueur et en angle pour toute surface dont la courbure de Gauss est non nulle.
En particulier, il est impossible de plaquer une image plane sur une sphère sans déformation. C’est un résultat fondamental de géométrie différentielle : la courbure de Gauss est un invariant intrinsèque de la surface (theorema egregium de Gauss). Une sphère a une courbure de Gauss positive constante (\(K = 1/R^2\)), tandis qu’un plan a une courbure nulle (\(K = 0\)). Aucune déformation sans étirement ne peut transformer l’une en l’autre.
Seules les surfaces développables (courbure de Gauss nulle, comme les cylindres et les cônes) peuvent être dépliées sans distorsion. En pratique, on cherche à minimiser les déformations lors du dépliage UV, en acceptant un compromis entre la distorsion des angles (conforme) et la distorsion des aires (authalique). La figure suivante montre un cas typique de déformation sur une sphère.
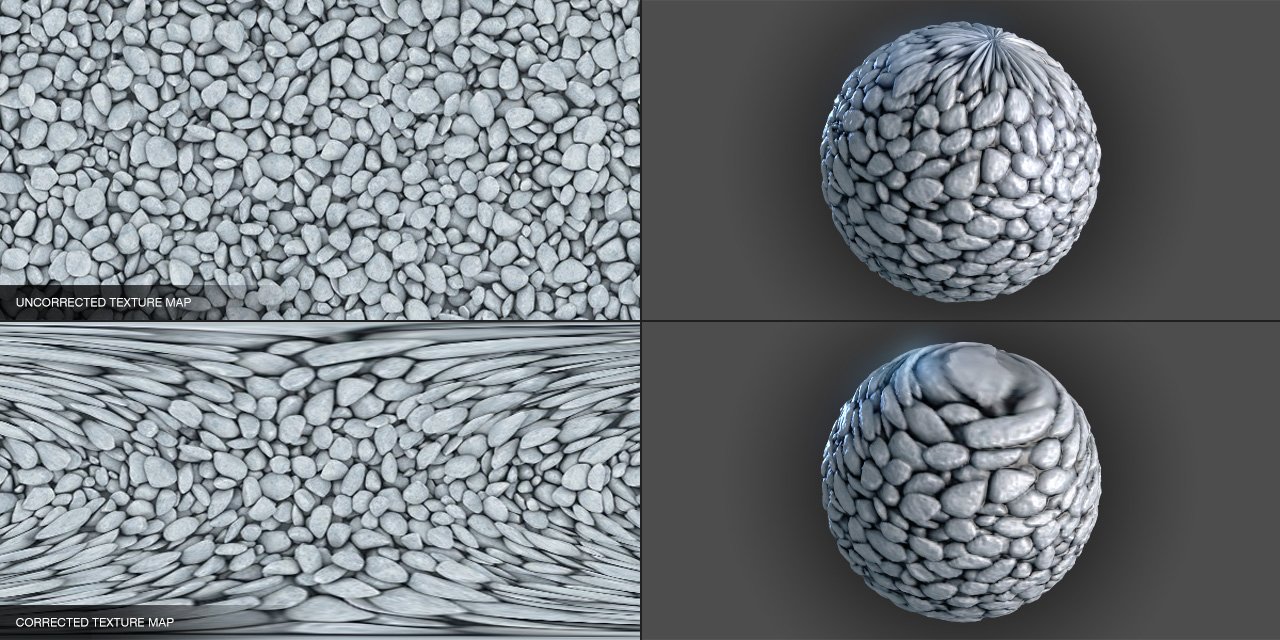
Déformation lors du placage d'une texture sur une sphère : étirement aux pôles.
Au-delà de la couleur (diffuse map), les textures sont utilisées pour stocker de nombreux types d’informations sur la surface :
Les coordonnées de texture sont stockées comme attribut de sommet, au même titre que les positions et les normales :
std::vector<vec2> uv = { uv_0, uv_1, uv_2, ... };Côté C++/OpenGL, la texture est chargée et envoyée au GPU :
// Chargement de l'image
int width, height, channels;
unsigned char* data = stbi_load("texture.png", &width, &height, &channels, 4);
// Création de la texture OpenGL
GLuint texture_id;
glGenTextures(1, &texture_id);
glBindTexture(GL_TEXTURE_2D, texture_id);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, width, height, 0,
GL_RGBA, GL_UNSIGNED_BYTE, data);
// Activation dans le fragment shader (unité de texture 0)
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, texture_id);
glUniform1i(glGetUniformLocation(shader, "texture_image"), 0);Lors du rendu, le fragment shader reçoit les coordonnées de texture
\((u, v)\) interpolées de manière
barycentrique entre les trois sommets du triangle courant. Il lit
ensuite la couleur dans l’image de texture à cette position grâce à la
fonction texture() :
uniform sampler2D texture_image; // la texture, envoyée depuis le CPU
in vec2 fragment_uv; // coordonnées interpolées
out vec4 FragColor;
void main() {
vec4 color = texture(texture_image, fragment_uv);
FragColor = color;
}La variable sampler2D représente une référence vers une
texture stockée en VRAM. La fonction texture(sampler, uv)
réalise l’échantillonnage : elle convertit les
coordonnées normalisées \((u, v) \in [0,
1]^2\) en coordonnées pixel dans l’image, puis renvoie la couleur
correspondante.
Les coordonnées \((u, v)\) interpolées tombent rarement exactement sur le centre d’un pixel de la texture (appelé texel). Le GPU doit donc interpoler entre les texels voisins. Ce processus est appelé filtrage de texture. Il intervient dans deux cas :
Les modes de filtrage les plus courants sont :
GL_NEAREST) : sélectionne le
texel le plus proche. Rendu pixelisé mais rapide. Utile pour un style
pixel-art.GL_LINEAR) : interpole
linéairement entre les 4 texels les plus proches. Rendu lisse, standard
pour la magnification.GL_LINEAR_MIPMAP_LINEAR)
: interpolation bilinéaire + interpolation entre deux niveaux de
mipmap (voir ci-dessous). Standard pour la
minification.Configuration en OpenGL :
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR);Les mipmaps sont des versions pré-calculées de la texture à résolutions décroissantes (chaque niveau divise la résolution par 2). Lors de la minification, le GPU choisit le niveau de mipmap dont la résolution est la plus adaptée à la taille du triangle à l’écran, puis interpole si nécessaire.
Pour une texture de \(1024 \times 1024\), la chaîne de mipmaps contient les niveaux : \(1024^2\), \(512^2\), \(256^2\), …, \(2^2\), \(1^2\) (soit 11 niveaux). L’espace mémoire total est seulement \(\frac{4}{3}\) de la texture originale.
Les mipmaps réduisent l’aliasing (scintillement des textures vues de loin) et améliorent les performances (les textures lointaines sont lues dans des niveaux de résolution faible, mieux exploités par le cache mémoire du GPU).
Génération automatique en OpenGL :
glGenerateMipmap(GL_TEXTURE_2D);Lorsque les coordonnées de texture sortent de l’intervalle \([0, 1]\), le comportement dépend du mode de wrapping :
GL_REPEAT) : la texture se
répète indéfiniment. La coordonnée \(u =
2.3\) est interprétée comme \(u =
0.3\). Utile pour les textures carrelables (briques, herbe,
etc.).GL_MIRRORED_REPEAT) :
la texture se répète en alternant son orientation, évitant les coutures
visibles aux bords.GL_CLAMP_TO_EDGE) : les
coordonnées hors \([0, 1]\) sont
ramenées au bord de la texture. Les pixels hors limites prennent la
couleur du bord le plus proche.Configuration en OpenGL :
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);Toutes les textures (couleur, normales, spéculaire, etc.) partagent
les mêmes coordonnées UV et utilisent le même mécanisme
d’échantillonnage. Elles sont simplement lues dans des
sampler2D différents dans le fragment shader :
uniform sampler2D diffuse_map;
uniform sampler2D normal_map;
uniform sampler2D specular_map;
void main() {
vec3 color = texture(diffuse_map, fragment.uv).rgb;
vec3 normal = texture(normal_map, fragment.uv).rgb * 2.0 - 1.0;
float spec = texture(specular_map, fragment.uv).r;
// ...
}Une skybox est une boîte texturée représentant l’environnement distant (ciel, paysage). Elle est toujours centrée sur la position de la caméra, ce qui donne l’impression d’un paysage infini, comme on le voit ci-dessous.

Le principe d’implémentation est le suivant :
void display() {
glDepthMask(GL_FALSE); // désactiver l'écriture dans le depth buffer
draw(skybox, environment);
glDepthMask(GL_TRUE); // réactiver l'écriture
// dessiner les autres objets ...
}L’environment mapping simule la réflexion de l’environnement (skybox) sur une surface brillante. Cela donne l’impression que l’objet reflète le monde autour de lui.
Le principe, schématisé ci-dessous, est de calculer, pour chaque fragment, la direction de réflexion du vecteur vue par rapport à la normale, puis de lire la couleur correspondante dans la texture de la skybox.

vec3 V = normalize(camera_position - fragment.position);
vec3 R_skybox = reflect(-V, N);
vec4 color_env = texture(image_skybox, R_skybox);Le normal mapping consiste à modifier les normales de la surface à l’aide d’une image (la normal map) pour simuler des détails géométriques plus fins que les triangles du maillage. La géométrie réelle du triangle ne change pas : seule la normale utilisée dans le calcul d’illumination est modifiée, ce qui donne l’illusion de relief visible sur la comparaison suivante.

Les normales d’une normal map ne sont pas stockées en coordonnées monde (qui dépendraient de l’orientation de l’objet), mais dans un repère local au triangle appelé espace tangent \((T, B, N)\) :
Ce repère est défini par les coordonnées de texture \((u, v)\) et les positions des sommets du triangle :
\[ \begin{cases} p_0 - p_1 = (u_0 - u_1) \, T + (v_0 - v_1) \, B \\ p_2 - p_1 = (u_2 - u_1) \, T + (v_2 - v_1) \, B \\ N = T \times B \end{cases} \]
Ce système de deux équations vectorielles (soit 6 équations scalaires) permet de résoudre \(T\) et \(B\) (6 inconnues). En notation matricielle, pour les composantes \(x\) par exemple :
\[ \begin{pmatrix} T_x \\ B_x \end{pmatrix} = \frac{1}{(u_0 - u_1)(v_2 - v_1) - (u_2 - u_1)(v_0 - v_1)} \begin{pmatrix} v_2 - v_1 & -(v_0 - v_1) \\ -(u_2 - u_1) & u_0 - u_1 \end{pmatrix} \begin{pmatrix} (p_0 - p_1)_x \\ (p_2 - p_1)_x \end{pmatrix} \]
et de même pour les composantes \(y\) et \(z\). Les vecteurs \(T\) et \(B\) sont ensuite normalisés.
Chaque pixel de la normal map stocke une normale perturbée en composantes \((r, g, b) \in [0, 1]^3\), encodant les composantes dans l’espace tangent sur \([-1, 1]\) :
\[ n_{\text{tangent}} = 2 \begin{pmatrix} r \\ g \\ b \end{pmatrix} - \begin{pmatrix} 1 \\ 1 \\ 1 \end{pmatrix} \]
La composante \(b\) (bleue) correspond à la direction de la normale géométrique \(N\). C’est pourquoi les normal maps apparaissent bleutées : la plupart des normales sont proches de \((0, 0, 1)\) dans l’espace tangent, ce qui donne \((0.5, 0.5, 1.0)\) en RGB. On peut observer cet encodage sur les images ci-dessous.


Normal map : les normales sont encodées en couleur dans l'espace tangent (gauche). Application sur un mur en briques (droite).
La normale finale en coordonnées monde est obtenue par changement de base :
\[ n_{\text{world}} = \text{TBN} \times n_{\text{tangent}} = T \cdot n_x + B \cdot n_y + N \cdot n_z \]
où \(\text{TBN} = (T \mid B \mid N)\) est la matrice \(3 \times 3\) dont les colonnes sont les vecteurs du repère tangent.
Vertex shader : calcul du repère tangent et passage au fragment shader.
layout(location = 0) in vec3 vertex_position;
layout(location = 1) in vec3 vertex_normal;
layout(location = 2) in vec2 vertex_uv;
layout(location = 3) in vec3 vertex_tangent;
out struct fragment_data {
vec3 position;
vec2 uv;
mat3 TBN;
} fragment;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
void main() {
vec4 pos_world = model * vec4(vertex_position, 1.0);
mat3 normalMatrix = mat3(transpose(inverse(model)));
vec3 T = normalize(normalMatrix * vertex_tangent);
vec3 N = normalize(normalMatrix * vertex_normal);
vec3 B = cross(N, T);
fragment.position = pos_world.xyz;
fragment.uv = vertex_uv;
fragment.TBN = mat3(T, B, N);
gl_Position = projection * view * pos_world;
}Fragment shader : lecture de la normal map et calcul de l’illumination.
in struct fragment_data {
vec3 position;
vec2 uv;
mat3 TBN;
} fragment;
uniform sampler2D normal_map;
uniform vec3 light_position;
out vec4 FragColor;
void main() {
// Lire la normale dans la normal map et la convertir de [0,1] à [-1,1]
vec3 n_tangent = texture(normal_map, fragment.uv).rgb * 2.0 - 1.0;
// Transformer vers l'espace monde
vec3 N = normalize(fragment.TBN * n_tangent);
// Illumination avec la normale perturbée
vec3 L = normalize(light_position - fragment.position);
float diffuse = max(dot(N, L), 0.0);
// ...
}L’avantage de l’espace tangent est que la même normal map peut être réutilisée sur différents objets ou différentes parties d’un même objet, indépendamment de leur orientation dans le monde.
Le parallax mapping va plus loin que le normal mapping en déformant les coordonnées de texture elles-mêmes en fonction d’une carte de hauteur (height map). Alors que le normal mapping ne modifie que l’illumination (la silhouette reste plate), le parallax mapping crée une impression de décalage géométrique : les zones hautes semblent avancer et les zones basses reculer, en particulier lorsque l’on observe la surface sous un angle rasant.
Considérons un fragment sur une surface plane. Sans parallax mapping, on lirait la texture aux coordonnées \((u, v)\) de ce fragment. Mais si la surface avait réellement du relief, le rayon de vue aurait intersecté la surface à un point différent, décalé horizontalement. Le parallax mapping approxime ce décalage, comme le montre le schéma ci-dessous.

Soit \(V\) le vecteur de vue exprimé dans l’espace tangent et \(h\) la hauteur lue dans la height map au point courant. Le décalage des coordonnées de texture est :
\[ (u', v') = (u, v) + h \cdot \frac{(V_x, V_y)}{V_z} \]
La division par \(V_z\) amplifie le décalage aux angles rasants (quand \(V_z\) est petit), ce qui correspond au comportement physique attendu : la parallaxe est plus visible sous un angle oblique.
Fragment shader avec parallax mapping :
in struct fragment_data {
vec3 position;
vec2 uv;
mat3 TBN;
} fragment;
uniform sampler2D diffuse_map;
uniform sampler2D height_map;
uniform sampler2D normal_map;
uniform vec3 camera_position;
uniform float height_scale; // contrôle l'amplitude du relief (~0.05-0.1)
out vec4 FragColor;
void main() {
// Vecteur de vue dans l'espace tangent
vec3 V_world = normalize(camera_position - fragment.position);
vec3 V_tangent = normalize(transpose(fragment.TBN) * V_world);
// Lire la hauteur et calculer le décalage
float h = texture(height_map, fragment.uv).r;
vec2 uv_offset = h * height_scale * V_tangent.xy / V_tangent.z;
vec2 uv_parallax = fragment.uv + uv_offset;
// Utiliser les coordonnées décalées pour la texture et la normal map
vec3 color = texture(diffuse_map, uv_parallax).rgb;
vec3 n_tangent = texture(normal_map, uv_parallax).rgb * 2.0 - 1.0;
vec3 N = normalize(fragment.TBN * n_tangent);
// Illumination avec la normale et la couleur décalées
// ...
}Le parallax mapping simple est une approximation du premier ordre qui fonctionne bien pour des reliefs faibles. Pour des reliefs plus prononcés, il produit des artefacts (glissements, distorsions). Le Steep Parallax Mapping (ou Parallax Occlusion Mapping) améliore la qualité en parcourant le rayon de vue pas à pas à travers la carte de hauteur :
vec2 steep_parallax(vec2 uv, vec3 V_tangent, float height_scale) {
const int num_steps = 32;
float step_size = 1.0 / float(num_steps);
float current_depth = 0.0;
vec2 delta_uv = V_tangent.xy / V_tangent.z * height_scale / float(num_steps);
vec2 current_uv = uv;
float current_height = texture(height_map, current_uv).r;
for(int i = 0; i < num_steps; i++) {
if(current_depth >= current_height) break;
current_uv += delta_uv;
current_height = texture(height_map, current_uv).r;
current_depth += step_size;
}
return current_uv;
}Cette méthode est plus coûteuse (une lecture de texture par étape), mais produit des résultats visuellement convaincants même pour des reliefs importants, avec une gestion correcte de l’auto-occultation des détails du relief.
De nombreux phénomènes visuels — fumée, feu, eau qui jaillit, explosions, étincelles, neige — ne possèdent pas de surface nette et bien définie. Contrairement à un objet solide (un personnage, un bâtiment), ces effets sont diffus : ils sont composés d’un grand nombre d’éléments minuscules qui évoluent de manière partiellement aléatoire. Tenter de les modéliser par un maillage classique serait à la fois coûteux et inadapté, car leur forme change constamment et ne correspond pas à une surface géométrique stable.
Un système de particules répond à ce besoin. Le concept, introduit par William Reeves en 1983 pour les effets du film Star Trek II, repose sur une idée simple : modéliser ces phénomènes comme un ensemble d’éléments indépendants (les particules), chacun suivant une règle de comportement simple. C’est le comportement collectif de milliers de particules qui produit l’effet visuel recherché.
Chaque particule est caractérisée par :
Le cycle de vie d’une particule suit quatre phases. L’émission : la particule est créée à une position initiale avec une vitesse et des attributs initiaux (éventuellement aléatoires). La simulation : à chaque pas de temps, sa position est mise à jour selon une équation de mouvement, et ses attributs peuvent évoluer (par exemple, la transparence augmente progressivement pour simuler la dissipation de la fumée). La mort : lorsque la durée de vie est écoulée, la particule est désactivée. Le recyclage : en pratique, on pré-alloue un tableau de particules de taille fixe. Lorsqu’une particule meurt, son emplacement est réutilisé pour une nouvelle particule, évitant les allocations dynamiques coûteuses.
La représentation géométrique la plus simple est la sphère : chaque particule est affichée comme une petite sphère dans la scène 3D. Cette approche est intuitive mais coûteuse en géométrie pour un grand nombre de particules. Pour des effets plus détaillés et plus performants, on utilise des billboards (voir section suivante).
Le cas le plus courant est la chute libre sous l’effet de la gravité. En physique, la deuxième loi de Newton donne l’accélération \(a = g\) (constante), ce qui, par double intégration, fournit l’équation du mouvement :
\[ p(t) = \frac{1}{2} \, g \, t^2 + v_0 \, t + p_0 \]
avec :
Cette équation décrit une parabole : la particule monte (si \(v_0\) a une composante verticale positive), ralentit sous l’effet de la gravité, puis retombe. C’est exactement la trajectoire d’un projectile.
Pour créer un effet de fontaine ou de jet, on introduit de la randomisation dans les conditions initiales. C’est cette variabilité entre les particules qui donne un aspect naturel à l’ensemble : si toutes les particules avaient exactement les mêmes paramètres, elles suivraient toutes la même trajectoire et l’effet serait visuellement pauvre.
// Exemple : émission d'une particule
vec3 p0 = emitter_position + rand_vec3(-0.1f, 0.1f);
vec3 v0 = vec3(0, 5, 0) + rand_vec3(-1.0f, 1.0f);
float lifetime = rand(1.0f, 3.0f);La vitesse se déduit par dérivation :
\[ v(t) = g \, t + v_0 \]
À chaque pas de temps, les particules dont la durée de vie est écoulée sont supprimées, et de nouvelles particules sont émises. En pratique, l’émetteur produit un flux constant (par exemple 100 particules par seconde), ce qui maintient un nombre stable de particules actives dans la scène.
Lorsqu’une particule rencontre un obstacle (par exemple le sol à \(y = 0\)), il est possible de simuler un rebond. L’idée est de détecter l’instant exact de la collision, puis de redémarrer la simulation avec une vitesse modifiée. Le principe est le suivant :
\[ p_y(t_i) = \frac{1}{2} g_y \, t_i^2 + v_{0,y} \, t_i + p_{0,y} = 0 \]
\[ v(t_i) = g \, t_i + v_0 \]
\[ v_y^{\text{après}} = -\epsilon \, v_y(t_i) \]
Le coefficient \(\epsilon\) contrôle le comportement du rebond : \(\epsilon = 1\) correspond à un rebond parfaitement élastique (la particule repart avec la même énergie), tandis que \(\epsilon = 0\) signifie que la particule est totalement absorbée par la surface (elle s’arrête). En pratique, on utilise des valeurs intermédiaires (\(\epsilon \approx 0.6\text{-}0.8\)) pour obtenir un effet réaliste.
La particule repart alors avec cette nouvelle vitesse comme condition initiale, produisant une trajectoire par morceaux. En répétant ce processus, on obtient une séquence de rebonds d’amplitude décroissante jusqu’à ce que la particule s’immobilise ou que sa durée de vie expire.
Ce principe se généralise à des obstacles quelconques : pour un plan oblique défini par sa normale \(\hat{n}\), la composante inversée est la projection de la vitesse sur cette normale : \(v^{\text{après}} = v(t_i) - (1 + \epsilon)(v(t_i) \cdot \hat{n})\,\hat{n}\).
Les trajectoires ne sont pas nécessairement contraintes par la physique. En informatique graphique, l’objectif est souvent de produire un effet visuel convaincant plutôt qu’une simulation fidèle. On peut donc définir des mouvements procéduraux arbitraires, guidés par l’esthétique plutôt que par les lois de Newton.
Quelques exemples classiques :
La différence avec la simulation physique est la liberté artistique : le créateur peut ajuster les paramètres de mouvement pour obtenir exactement l’effet souhaité, sans être contraint par le réalisme. Un vortex de particules dans un jeu vidéo n’a pas besoin de respecter les équations de Navier-Stokes pour être visuellement convaincant.
Afficher chaque particule comme une sphère 3D est coûteux : une sphère lisse nécessite des centaines de triangles, et un système de 10 000 particules représenterait alors des millions de triangles. Plutôt que de dessiner de la géométrie 3D, on utilise des billboards (ou imposteurs) : des quadrangles texturés qui font toujours face à la caméra.
L’idée est de tromper l’oeil : puisqu’un quadrangle orienté face à la caméra apparaît toujours de face (sans perspective révélatrice), il suffit d’y appliquer une texture réaliste pour donner l’illusion d’un objet plus complexe. Le principe repose sur trois éléments :



Billboards : texture de fumée avec canal alpha (gauche), arbre composé de quadrangles texturés avec ses textures de feuillage (centre), effet de feu obtenu par accumulation de billboards (droite).
On distingue deux types de billboards selon leur axe de liberté :
Plusieurs extensions du concept existent :
Les billboards sont très courants en production pour le rendu de :
L’avantage principal est le rapport qualité/coût : un billboard ne nécessite que 4 sommets (2 triangles) par particule, contre des centaines pour une géométrie 3D complète. Pour un système de 10 000 particules, cela représente 20 000 triangles au lieu de plusieurs millions.
Le rendu des billboards repose sur la transparence, qui est un problème fondamentalement difficile en rastérisation. En ray tracing, la transparence est naturelle : un rayon qui traverse un objet semi-transparent continue son chemin et accumule les couleurs des objets rencontrés. En rastérisation, en revanche, chaque triangle est dessiné indépendamment dans le framebuffer, sans connaissance des triangles qui seront dessinés ensuite. La gestion de la transparence nécessite donc des mécanismes explicites. Il n’existe pas de solution parfaite, mais plusieurs approches complémentaires.
La transparence en OpenGL fonctionne par mélange de couleurs (blending) : la couleur du fragment courant est combinée avec la couleur déjà présente dans le framebuffer, en utilisant le canal alpha (\(\alpha\)) comme facteur de pondération.
L’activation se fait explicitement :
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
// ... appels de dessin des objets transparents ...
glDisable(GL_BLEND);La formule de mélange résultante est :
\[ C_{\text{new}} = \alpha \cdot C_{\text{current}} + (1 - \alpha) \cdot C_{\text{previous}} \]
avec :
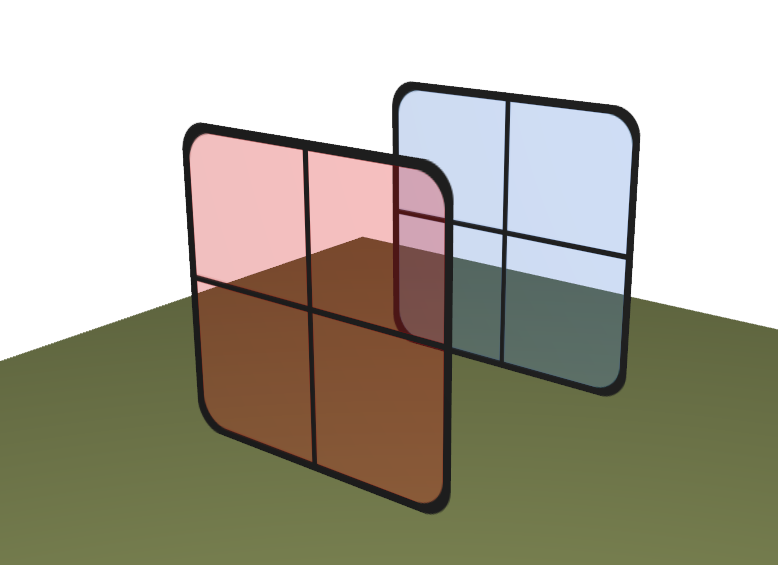
Point important : l’ordre de dessin compte. La couleur \(C_{\text{previous}}\) dépend de ce qui a été dessiné avant le fragment courant. Si deux objets transparents se superposent, le résultat dépend de l’ordre dans lequel ils ont été rendus. C’est une différence majeure avec les objets opaques, pour lesquels le depth buffer garantit un résultat correct quel que soit l’ordre de dessin.
Il existe d’autres modes de blending, définis par des combinaisons
différentes de glBlendFunc. Par exemple, le
blending additif (GL_SRC_ALPHA, GL_ONE)
additionne les couleurs sans atténuer la destination : \(C_{\text{new}} = \alpha \cdot C_{\text{current}} +
C_{\text{previous}}\). Ce mode est particulièrement adapté aux
effets lumineux (feu, étincelles, lasers), car les couleurs s’accumulent
et produisent des zones de forte luminosité.
Pour obtenir un rendu correct des objets transparents, il faut respecter une contrainte fondamentale : les objets transparents doivent être dessinés du plus loin au plus proche (back-to-front). En effet, la formule de blending mélange la couleur du fragment courant avec ce qui est déjà dans le framebuffer. Pour que le résultat soit physiquement cohérent (un objet rouge semi-transparent devant un objet bleu), il faut que l’objet bleu (le plus loin) soit déjà dans le framebuffer quand on dessine l’objet rouge (le plus proche).
L’approche standard suit ces étapes :
Dessiner tous les objets opaques normalement (avec le depth buffer activé en lecture et écriture). Cette étape remplit le depth buffer, ce qui empêchera les objets transparents d’apparaître devant les objets opaques qui les occultent.
Activer le blending et désactiver l’écriture dans le depth buffer (mais pas la lecture) :
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
glDepthMask(false); // désactiver l'écriture dans le depth buffer// Calcul de la profondeur pour le tri
vec4 p_proj = projection * modelview * vec4(position, 1.0);
float z_depth = p_proj.z / p_proj.w;Dessiner les objets transparents dans l’ordre trié (du plus loin au plus proche).
Rétablir l’état :
glDisable(GL_BLEND);
glDepthMask(true);Le code complet de l’algorithme :
// 1. Objets opaques
draw_opaque_objects();
// 2-3. Objets transparents
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
glDepthMask(false);
sort_by_depth(transparent_objects, camera_position); // du plus loin au plus proche
for(auto& obj : transparent_objects) {
draw(obj);
}
glDisable(GL_BLEND);
glDepthMask(true);La désactivation de l’écriture dans le depth buffer est essentielle : un objet transparent ne doit pas masquer les objets situés derrière lui. En revanche, la lecture du depth buffer reste active, ce qui empêche les objets transparents d’être dessinés devant les objets opaques qui les occultent.
Deux erreurs fréquentes lors du rendu transparent :
Erreur 1 : depth buffer en écriture sans tri. Si l’écriture dans le depth buffer reste activée et que les objets ne sont pas triés, un objet transparent proche peut écrire dans le depth buffer et empêcher le rendu des objets situés derrière lui. Le depth buffer “bloque” les fragments plus éloignés, même si l’objet au premier plan est semi-transparent et devrait laisser voir ce qui se trouve derrière. Le résultat est des artefacts visuels marqués : des morceaux d’objets disparaissent de manière incohérente, avec des “trous” dans la scène qui dépendent de l’ordre de soumission des triangles au GPU.
Erreur 2 : pas de tri, depth buffer en écriture désactivée. Sans tri mais avec l’écriture depth buffer désactivée, les objets transparents sont mélangés dans un ordre arbitraire. Pour des objets dont les couleurs sont proches et les formes diffuses (fumée, nuages, brouillard), l’ordre de mélange a peu d’impact visuel et le résultat est approximativement acceptable. Cette approche est parfois utilisée en pratique pour éviter le coût du tri — qui peut être significatif pour des milliers de particules — quand la qualité visuelle n’a pas besoin d’être parfaite. En revanche, pour des objets transparents aux couleurs vives et contrastées (vitraux, cristaux), l’absence de tri produit des artefacts visibles.
Pour les billboards dont la texture est soit entièrement opaque, soit entièrement transparente (pas de semi-transparence), une approche plus simple existe : le discard dans le fragment shader.
Le mot-clé discard arrête l’exécution du fragment shader
: rien n’est écrit dans le framebuffer ni dans le depth buffer pour ce
fragment. Il suffit de tester la valeur alpha de la texture :
uniform sampler2D image_texture;
in vec2 uv;
out vec4 FragColor;
void main() {
vec4 color = texture(image_texture, uv);
float alpha_limit = 0.6;
if(color.a < alpha_limit) {
discard; // fragment entièrement transparent : on l'ignore
}
FragColor = color;
}Avantages :
Inconvénients :
alpha_limit crée une
frontière nette).Un système de particules peut contenir des milliers, voire des
centaines de milliers d’éléments partageant la même
géométrie (par exemple un quadrangle pour un billboard) mais
avec des paramètres différents (position, couleur,
taille). L’approche naïve consiste à appeler glDrawElements
pour chaque particule :
for(int k = 0; k < N; ++k) {
update_uniforms(k); // position, couleur, taille...
draw(shape); // glDrawElements(...)
}Cette boucle est très inefficace. Pour comprendre
pourquoi, il faut considérer l’architecture CPU/GPU : chaque appel à
glDrawElements ne se contente pas de lancer le rendu. Il
provoque une synchronisation entre le CPU et le GPU :
le driver OpenGL doit valider l’état courant (shader actif, uniforms,
textures, buffers), préparer la commande, et l’envoyer au GPU. Cette
surcharge par appel est à peu près constante, quelle que soit la taille
de la géométrie. Le graphique ci-dessous, issu de la documentation
NVIDIA, illustre le coût relatif des différents changements d’état :
même les opérations les moins coûteuses (mise à jour d’uniforms) sont
limitées à environ 10 millions par seconde.
Pour 15 000 particules composées de 50 triangles chacune, cela représente 15 000 appels de dessin et 750 000 sommets, mais c’est le nombre d’appels (et non le nombre de sommets) qui constitue le goulot d’étranglement côté CPU.
L’instancing résout ce problème en remplaçant les \(N\) appels de dessin par un unique appel qui demande au GPU de dessiner \(N\) copies de la même géométrie :
drawInstanced(shape, N); // glDrawElementsInstanced(..., N)L’instancing repose sur deux éléments :
Côté CPU : remplacement de
glDrawElements par glDrawElementsInstanced
:
// Au lieu de :
// glDrawElements(GL_TRIANGLES, count, GL_UNSIGNED_INT, 0);
// On utilise :
glDrawElementsInstanced(GL_TRIANGLES, count, GL_UNSIGNED_INT, 0, N);où \(N\) est le nombre d’instances (particules) à dessiner.
Côté shader : la variable built-in
gl_InstanceID permet de différencier chaque instance. Elle
contient l’indice de l’instance courante (de 0 à \(N-1\)) et permet de lire les paramètres
spécifiques à chaque particule :
// Vertex shader
uniform vec3 positions[MAX_PARTICLES]; // ou via un SSBO / texture
uniform vec3 colors[MAX_PARTICLES];
void main() {
vec3 offset = positions[gl_InstanceID];
vec3 color = colors[gl_InstanceID];
gl_Position = projection * view * vec4(vertex_position + offset, 1.0);
// ...
}Les gains de performance sont considérables. À titre d’exemple :
Le gain est important car l’instancing élimine le goulot d’étranglement CPU : au lieu de 15 000 aller-retours CPU→GPU, un seul suffit, et le GPU — dont l’architecture est conçue pour le traitement massivement parallèle — peut traiter les millions de sommets résultants sans difficulté.
L’instancing est la technique standard pour tout rendu nécessitant un grand nombre de copies d’une même géométrie : particules, végétation (herbe, arbres), foules, astéroïdes, etc. Pour des cas encore plus avancés (nombre d’instances variable, paramètres complexes), on peut remplacer les tableaux d’uniformes par des Shader Storage Buffer Objects (SSBOs) ou des textures de données, qui ne sont pas limités en taille comme les tableaux d’uniformes.
En informatique graphique, la création de formes naturelles (terrains, nuages, textures de pierre, de bois, d’eau) pose un défi : ces formes sont trop complexes et irrégulières pour être modélisées manuellement, mais elles ne sont pas non plus purement aléatoires — elles possèdent une structure reconnaissable. Un amas de bruit blanc (valeurs aléatoires indépendantes à chaque pixel) ne ressemble à rien de naturel ; une texture peinte à la main est coûteuse à produire et limitée en résolution.
Le bruit procédural répond à ce besoin : une fonction mathématique qui génère un motif pseudo-aléatoire “à la demande”, avec des propriétés contrôlées :
Les bruits procéduraux les plus courants sont illustrés ci-dessous.



Exemples de bruits procéduraux : Perlin (gauche), Worley (centre), Flow (droite).
Les bruits procéduraux sont utilisés pour la génération de terrains, de textures, d’animations, et plus généralement pour toute forme complexe nécessitant un aspect naturel sans stockage explicite de données.
La construction d’un bruit procédural 1D repose sur deux ingrédients :
float hash(float n) {
return fract(sin(n) * 1e4);
}Cette fonction exploite le fait que \(\sin(n) \times 10^4\) produit des valeurs
dont les décimales varient de manière apparemment chaotique d’un entier
à l’autre, et fract extrait la partie fractionnaire pour
obtenir un résultat dans \([0,
1]\).
L’algorithme pour évaluer \(f(x)\) est :

La fonction résultante est :
Ce principe se généralise directement en 2D et 3D. En 2D, on utilise une grille d’entiers \((i, j)\) avec une valeur de hachage \(h(i, j)\) à chaque noeud, et on interpole bilinéairement dans chaque cellule. En 3D, l’interpolation est trilinéaire. Le coût de calcul augmente avec la dimension (4 évaluations de hash en 2D, 8 en 3D), mais reste raisonnable pour un calcul en temps réel.
Un bruit continu avec une fréquence fixe produit un motif trop régulier pour simuler des formes naturelles. La nature présente des détails à toutes les échelles : une montagne vue de loin a une silhouette dentelée ; en se rapprochant, on découvre des crêtes, puis des rochers, puis des cailloux, puis des grains de sable. Chaque niveau de zoom révèle de nouveaux détails. De même, une côte maritime est découpée à l’échelle du kilomètre, du mètre et du centimètre. Un nuage possède des volutes à toutes les tailles.
Le concept de fractale formalise cette idée : une forme est fractale si elle présente une auto-similarité, c’est-à-dire que sa structure se répète (approximativement) à différentes échelles. Des exemples classiques sont le flocon de Koch (dont le périmètre augmente à chaque itération mais dont l’aire reste bornée), le triangle de Sierpinski, ou encore les formes naturelles comme le chou romanesco dont les spirales se répètent à plusieurs niveaux d’échelle.

L’intérêt des fractales en informatique graphique est qu’une règle simple appliquée récursivement peut produire des formes d’une grande complexité visuelle, rappelant les structures naturelles. Cependant, les fractales mathématiques classiques (Mandelbrot, Sierpinski) sont difficiles à contrôler pour un usage artistique. En pratique, on utilise plutôt la sommation de bruits à différentes fréquences, comme dans le bruit de Perlin.
Le bruit de Perlin (Ken Perlin, An Image Synthesizer, SIGGRAPH 1985) est le premier algorithme de bruit procédural et reste le plus utilisé en informatique graphique. Cette contribution lui a valu un Academy Award technique en 1997. Son idée centrale est de reproduire le principe fractal de la nature en sommant des fonctions pseudo-aléatoires avec des fréquences croissantes et des amplitudes décroissantes :
\[ P(x) = \sum_{k=0}^{N} \alpha^k \, f(\omega^k \, x) \]
avec :
La figure ci-dessous montre la décomposition en octaves : la première octave donne la forme globale, les suivantes ajoutent des détails de plus en plus fins.
En 2D, la formule devient :
\[ P(u, v) = \sum_{k=0}^{N} \alpha^k \, f(2^k \, u, \, 2^k \, v) \]
Les images ci-dessous illustrent l’accumulation progressive des octaves en 2D.





Accumulation des octaves du bruit de Perlin en 2D : de 1 octave (gauche) à 5 octaves (droite).
Les paramètres typiques sont \(N \approx 5\text{-}9\), \(\alpha \approx 0.3\text{-}0.6\) et \(\omega = 2\). L’ajustement de ces paramètres permet de contrôler l’aspect du bruit : plus de détails avec \(N\) grand, détails plus marqués avec \(\alpha\) proche de 1.
Le bruit de Perlin est utilisé pour la génération de quasiment toutes les formes complexes en informatique graphique. Sa simplicité et sa versatilité expliquent son succès : en modifiant les paramètres ou en combinant le bruit avec d’autres opérations mathématiques, on obtient une grande variété d’effets.
Terrain procédural : l’application la plus directe consiste à utiliser le bruit comme carte de hauteur (height map). On définit une surface plane \((x, y)\) et on déplace chaque point verticalement selon la valeur du bruit :
\[ z(x, y) = P(x, y) \]
La hauteur de chaque point du terrain est directement donnée par la valeur du bruit. Les basses fréquences (premières octaves) définissent les grandes structures (vallées, montagnes), tandis que les hautes fréquences ajoutent les détails (rochers, aspérités). Le résultat ressemble à un paysage montagneux naturel, car les vrais terrains sont eux aussi formés par des processus multi-échelles (tectonique, érosion, gel).

Texture de crête (ridge) : en prenant la valeur absolue du bruit de base :
\[ \text{ridge}(x) = \sum_k \alpha^k \, |f(\omega^k \, x)| \]
La valeur absolue crée des plis (cusps) aux endroits où le bruit passe par zéro : au lieu d’une transition douce positive→négative, on obtient un V pointu. Ces plis forment des arêtes vives qui rappellent les crêtes montagneuses, les veines d’une feuille, ou les nervures du bois.
Texture de marbre : en utilisant le bruit comme perturbation d’une fonction sinusoïdale :
\[ \text{marble}(x) = \sin\!\Big(x + \sum_k \alpha^k \, |f(\omega^k \, x)|\Big) \]
L’idée est que le sinus produit naturellement des bandes régulières (comme les strates d’une pierre), et le bruit déforme ces bandes de manière irrégulière. Les ondulations du sinus, perturbées par le bruit, produisent un motif veiné similaire au marbre. En ajustant l’amplitude de la perturbation, on contrôle l’irrégularité des veines.

Textures animées : le bruit peut être étendu au temps pour créer des animations :
Ces techniques sont omniprésentes dans les jeux vidéo et les films : la surface de l’eau, le mouvement des nuages, la déformation de la lave, les effets de distorsion thermique sont généralement basés sur des variantes de bruit de Perlin animé.
L’algorithme original de Perlin présente certaines limitations qui ont motivé des améliorations successives.
Dans l’algorithme original (appelé value noise), chaque noeud de la grille stocke une valeur scalaire pseudo-aléatoire \(h(i, j) \in [0, 1]\), et on interpole ces valeurs. Le problème est que si deux noeuds voisins ont des valeurs proches (par exemple \(h = 0.7\) et \(h = 0.72\)), le bruit varie très peu dans cette zone, produisant une fréquence locale plus basse que prévu. La fréquence du bruit est donc irrégulière d’une cellule à l’autre.
Le gradient noise (Ken Perlin, 2002) corrige ce problème en associant à chaque noeud \((i, j)\) un vecteur gradient pseudo-aléatoire \(g_{i,j}\) (un vecteur unitaire de direction aléatoire) plutôt qu’un scalaire. L’algorithme pour évaluer le bruit en un point \(p = (x, y)\) est :
La propriété clé est que le produit scalaire \(g_{i,j} \cdot d\) est nul au noeud lui-même (car \(d = 0\) au noeud). Le bruit passe donc par zéro à chaque noeud de la grille, ce qui garantit exactement une oscillation par unité dans chaque direction. La fréquence est ainsi parfaitement contrôlée et homogène sur tout le domaine, ce qui donne un résultat visuellement plus régulier que le value noise.
En pseudocode :
float gradient_noise(float x, float y) {
int i = floor(x), j = floor(y);
float u = x - i, v = y - j; // coordonnées locales dans [0,1]²
// Gradients aux 4 coins
vec2 g00 = gradient(i, j );
vec2 g10 = gradient(i+1, j );
vec2 g01 = gradient(i, j+1);
vec2 g11 = gradient(i+1, j+1);
// Produits scalaires (contribution de chaque coin)
float d00 = dot(g00, vec2(u, v ));
float d10 = dot(g10, vec2(u-1, v ));
float d01 = dot(g01, vec2(u, v-1));
float d11 = dot(g11, vec2(u-1, v-1));
// Interpolation smoothstep
float sx = smoothstep(u), sy = smoothstep(v);
return mix(mix(d00, d10, sx), mix(d01, d11, sx), sy);
}Le Simplex Noise (Ken Perlin, 2001) remplace la grille cartésienne par un pavage de simplexes. Un simplexe est le polytope le plus simple en dimension \(d\) : un segment en 1D, un triangle en 2D, un tétraèdre en 3D. En 2D, l’espace est donc pavé par des triangles équilatéraux au lieu de carrés.
L’algorithme comporte trois étapes principales :
1. Localisation du simplexe (skewing). Pour déterminer dans quel triangle se trouve un point \((x, y)\), on applique une transformation de déformation (skew) qui transforme la grille de triangles en une grille carrée, facilitant la localisation :
\[ (x', y') = \Big(x + \frac{\sqrt{3} - 1}{2}(x + y), \;\; y + \frac{\sqrt{3} - 1}{2}(x + y)\Big) \]
Dans l’espace déformé, on identifie le carré \((\lfloor x' \rfloor, \lfloor y' \rfloor)\), puis on détermine dans quel triangle du carré on se trouve (diagonal supérieure ou inférieure) en testant si \(x' - \lfloor x' \rfloor > y' - \lfloor y' \rfloor\).
2. Calcul des contributions. Chaque simplexe a \(d + 1\) sommets (3 en 2D). Pour chaque sommet, on calcule une contribution locale en utilisant une fonction d’atténuation radiale au lieu d’une interpolation :
\[ \text{contribution}_k = \max(0, \; r^2 - \|d_k\|^2)^4 \cdot (g_k \cdot d_k) \]
où \(d_k\) est le vecteur déplacement du sommet \(k\) vers le point évalué, \(g_k\) est le gradient pseudo-aléatoire au sommet, et \(r\) est un rayon d’influence (typiquement \(r^2 = 0.5\) en 2D). La puissance 4 assure une décroissance rapide et lisse, avec continuité \(C^2\).
3. Sommation. Le bruit final est la somme des contributions des \(d + 1\) sommets :
\[ \text{simplex}(p) = \sum_{k=0}^{d} \text{contribution}_k \]
Les avantages par rapport au bruit sur grille sont les suivants :
Pour aller plus loin : A. Lagae et al., A Survey of Procedural Noise Functions, Computer Graphics Forum (Eurographics STAR), 2010.
En informatique graphique, les rotations interviennent constamment : orienter un personnage, faire tourner la caméra autour d’un objet, animer l’ouverture d’une porte, interpoler entre deux poses d’un squelette d’animation. Or, contrairement aux translations (qui sont naturellement décrites par un simple vecteur \(\mathbf{t} \in \mathbb{R}^3\)), les rotations 3D posent un problème de représentation non trivial.
Une rotation en 3D possède 3 degrés de liberté : intuitivement, on peut tourner autour de l’axe \(x\), de l’axe \(y\), et de l’axe \(z\), ce qui donne trois paramètres indépendants. Pourtant, les rotations ne forment pas un espace vectoriel — on ne peut pas simplement additionner deux rotations comme on additionne deux vecteurs.
Il n’existe pas de représentation parfaite : chaque formalisme fait un compromis entre compacité, facilité de calcul, stabilité numérique et capacité d’interpolation. Les quatre représentations principales utilisées en pratique sont :
La représentation la plus directe d’une rotation est la matrice de rotation \(R \in \mathbb{R}^{3 \times 3}\), satisfaisant deux contraintes :
\[ R^T R = I \quad \text{et} \quad \det(R) = 1 \]
La première condition (\(R^T R = I\)) signifie que les colonnes de \(R\) forment une base orthonormée : elles sont de norme 1 et mutuellement orthogonales. Géométriquement, la rotation transforme le repère canonique \((\mathbf{e}_x, \mathbf{e}_y, \mathbf{e}_z)\) en un nouveau repère orthonormé \((R \mathbf{e}_x, R \mathbf{e}_y, R \mathbf{e}_z)\), qui correspond aux colonnes de \(R\). La seconde condition (\(\det(R) = 1\)) distingue les rotations propres des réflexions (qui vérifient \(\det = -1\)).
La matrice s’applique directement à un vecteur : \(\mathbf{v}' = R \, \mathbf{v}\). La composition de deux rotations correspond au produit matriciel \(R_{\text{total}} = R_1 \, R_2\), et l’inverse d’une rotation est simplement la transposée : \(R^{-1} = R^T\) (conséquence directe de \(R^T R = I\)).
Avantages : le calcul est direct (un produit matrice-vecteur), la composition est un simple produit matriciel, et c’est le format utilisé nativement par le GPU dans le pipeline de rendu.
Inconvénients : la matrice contient 9 coefficients pour seulement 3 degrés de liberté — les 6 contraintes d’orthogonalité sont implicites. Cela pose deux problèmes en pratique. D’une part, les coefficients ne correspondent pas à des paramètres intuitifs (il est difficile de “lire” une matrice de rotation pour comprendre quelle rotation elle représente). D’autre part, les erreurs d’arrondi accumulées au fil des multiplications peuvent faire dériver la matrice hors de \(SO(3)\) : après de nombreuses compositions, \(R^T R\) n’est plus exactement \(I\), et la matrice introduit progressivement du scaling ou du shearing parasite. Il est alors nécessaire de réorthogonaliser périodiquement la matrice (par exemple via une décomposition polaire ou une SVD).
L’idée des angles d’Euler est de décomposer une rotation quelconque en trois rotations successives, chacune autour d’un axe fixe du repère. Cette approche est intuitive : plutôt que de manipuler 9 coefficients couplés, on travaille avec trois angles indépendants, chacun contrôlant une rotation autour d’un axe clairement identifié.
Les matrices de rotation élémentaires autour de chaque axe sont :
\[ R_x(\alpha) = \begin{pmatrix} 1 & 0 & 0 \\ 0 & \cos\alpha & -\sin\alpha \\ 0 & \sin\alpha & \cos\alpha \end{pmatrix}, \quad R_y(\beta) = \begin{pmatrix} \cos\beta & 0 & \sin\beta \\ 0 & 1 & 0 \\ -\sin\beta & 0 & \cos\beta \end{pmatrix}, \quad R_z(\gamma) = \begin{pmatrix} \cos\gamma & -\sin\gamma & 0 \\ \sin\gamma & \cos\gamma & 0 \\ 0 & 0 & 1 \end{pmatrix} \]
Chacune de ces matrices correspond à une rotation dans le plan orthogonal à l’axe considéré : \(R_x\) tourne dans le plan \((y, z)\), \(R_y\) dans le plan \((x, z)\), et \(R_z\) dans le plan \((x, y)\). On peut le vérifier en observant que la ligne et la colonne correspondant à l’axe de rotation contiennent les coefficients de l’identité (l’axe reste fixe).
La rotation résultante est le produit de ces trois matrices, par exemple \(R = R_z(\gamma) \, R_y(\beta) \, R_x(\alpha)\), qui signifie : d’abord une rotation d’angle \(\alpha\) autour de \(x\), puis d’angle \(\beta\) autour de \(y\), puis d’angle \(\gamma\) autour de \(z\) (rappel : les matrices s’appliquent de droite à gauche).
Il existe de multiples conventions pour l’ordre des axes. Les conventions dites Proper Euler (z-x-z, x-y-x, y-z-y, …) utilisent le même axe pour la première et la troisième rotation, tandis que les conventions Tait-Bryan (x-y-z, z-y-x, x-z-y, …) utilisent trois axes distincts. Au total, il existe 12 conventions possibles (6 Proper Euler + 6 Tait-Bryan). Il faut être particulièrement vigilant lors de l’import/export entre différents logiciels (Blender, Unity, Unreal, Maya…), car la convention utilisée n’est pas toujours la même, et une confusion conduit à des orientations incohérentes.
Avantages : paramètres compréhensibles (3 degrés de liberté), les animateurs peuvent interagir directement avec les courbes angulaires (en ajustant chaque angle indépendamment dans une timeline), largement utilisé en robotique (pour décrire l’orientation de bras articulés par rapport à des axes mécaniques).
Inconvénients : problème du gimbal lock, et l’interpolation ne suit pas le chemin le plus court.
Le gimbal lock (blocage de cardan) est une perte d’un degré de liberté qui survient lorsque deux des trois axes de rotation s’alignent pour certaines valeurs angulaires. Le nom provient des cardans (gimbals), ces anneaux concentriques utilisés dans les gyroscopes et les compas de marine : lorsque deux anneaux s’alignent, le dispositif perd la capacité de mesurer ou d’imposer une rotation dans l’une des directions.
Montrons ce phénomène mathématiquement en utilisant la même convention que ci-dessus. Considérons \(R = R_z(\gamma) \, R_y(\beta) \, R_x(\alpha)\) et posons \(\beta = \pi/2\). En développant le produit :
\[ R_z(\gamma) \, R_y(\pi/2) \, R_x(\alpha) = \begin{pmatrix} 0 & -\sin(\gamma - \alpha) & \cos(\gamma - \alpha) \\ 0 & \cos(\gamma - \alpha) & \sin(\gamma - \alpha) \\ -1 & 0 & 0 \end{pmatrix} \]
La matrice résultante ne dépend que de la différence \(\gamma - \alpha\) : modifier \(\alpha\) de \(+5°\) et \(\gamma\) de \(+5°\) produit exactement la même rotation. Deux des trois axes de rotation se sont alignés, et les paramètres \(\alpha\) et \(\gamma\) ne contrôlent plus des rotations indépendantes — ils agissent dans la même direction. On a perdu un degré de liberté : au lieu de 2 degrés de liberté effectifs (pour \(\alpha\) et \(\gamma\), \(\beta\) étant fixé), on ne dispose que d’un seul paramètre libre (\(\gamma - \alpha\)).
Ce problème est inhérent à toute décomposition en angles d’Euler, quelle que soit la convention choisie : il existe toujours une configuration singulière. En animation, cela se manifeste par des mouvements erratiques ou des “sauts” lorsque l’orientation passe au voisinage de la singularité.
L’autre limitation des angles d’Euler concerne l’interpolation : interpoler linéairement les trois angles entre deux orientations produit bien une rotation à chaque instant, mais le chemin suivi ne correspond pas nécessairement à la trajectoire de rotation la plus naturelle (le plus court chemin sur la sphère des orientations). Un objet qui tourne de A à B peut, avec les angles d’Euler, suivre un détour par des orientations intermédiaires non intuitives.
Le théorème de rotation d’Euler (à ne pas confondre avec les angles d’Euler) affirme que toute rotation en 3D peut être décrite par un axe unitaire \(\mathbf{n}\) (\(\|\mathbf{n}\| = 1\)) autour duquel s’effectue la rotation, et un angle \(\theta\) qui mesure l’amplitude de cette rotation. Ce résultat est intuitif : tout mouvement qui laisse un point fixe (l’origine) et préserve les distances est nécessairement une rotation autour d’un axe passant par ce point.
Cette représentation est particulièrement naturelle pour décrire la rotation qui amène un vecteur \(\mathbf{u}_1\) sur un vecteur \(\mathbf{u}_2\) (tous deux supposés unitaires). L’axe de rotation est perpendiculaire au plan formé par les deux vecteurs, et l’angle est celui qui les sépare :
Cas dégénérés : cette formule suppose que \(\mathbf{u}_1\) et \(\mathbf{u}_2\) ne sont pas colinéaires. Si \(\mathbf{u}_1 = \mathbf{u}_2\) (vecteurs parallèles), la rotation est l’identité. Si \(\mathbf{u}_1 = -\mathbf{u}_2\) (vecteurs antiparallèles, \(\theta = \pi\)), le produit vectoriel est nul et l’axe de rotation n’est pas déterminé de manière unique — n’importe quel vecteur perpendiculaire à \(\mathbf{u}_1\) convient. En pratique, on choisit un axe arbitraire perpendiculaire (par exemple via un produit vectoriel avec un vecteur de référence).
La rotation de twist autour de \(\mathbf{u}_2\) (rotation autour de l’axe d’arrivée après alignement) reste libre et peut être choisie arbitrairement — la paire \((\mathbf{n}, \theta)\) ci-dessus correspond au choix de twist nul, c’est-à-dire à la rotation “la plus simple” entre les deux vecteurs.
Avantages : représentation concise (3 degrés de liberté effectifs, encodés dans \(\mathbf{n}\) et \(\theta\), ou de manière équivalente dans le vecteur \(\theta \, \mathbf{n} \in \mathbb{R}^3\)), paramètres géométriquement compréhensibles.
Inconvénients : composer deux rotations axe-angle (c’est-à-dire trouver l’axe et l’angle de \(R_2 \circ R_1\) à partir de \((\mathbf{n}_1, \theta_1)\) et \((\mathbf{n}_2, \theta_2)\)) n’admet pas de formule simple — il faut passer par les matrices ou les quaternions. L’interpolation directe en axe-angle est également moins naturelle et moins robuste que via les quaternions lorsque les axes diffèrent : interpoler séparément l’axe et l’angle ne produit pas en général le chemin de rotation le plus court.
La question centrale est : étant donnés un axe \(\mathbf{n}\) et un angle \(\theta\), comment calculer le vecteur \(\mathbf{v}'\) obtenu en tournant \(\mathbf{v}\) ? L’idée est de décomposer \(\mathbf{v}\) en une composante parallèle à l’axe (qui ne bouge pas) et une composante perpendiculaire (qui tourne dans le plan orthogonal) :
\[ \mathbf{v}_\parallel = (\mathbf{v} \cdot \mathbf{n}) \, \mathbf{n}, \quad \mathbf{v}_\perp = \mathbf{v} - (\mathbf{v} \cdot \mathbf{n}) \, \mathbf{n} \]
La composante parallèle \(\mathbf{v}_\parallel\) est la projection de \(\mathbf{v}\) sur l’axe \(\mathbf{n}\). Elle est inchangée par la rotation (un vecteur aligné avec l’axe de rotation ne bouge pas). La composante perpendiculaire \(\mathbf{v}_\perp\) vit dans le plan orthogonal à \(\mathbf{n}\), et c’est elle qui tourne d’un angle \(\theta\).
Dans ce plan, on dispose de deux vecteurs orthogonaux : \(\mathbf{v}_\perp\) et \(\mathbf{n} \times \mathbf{v}_\perp = \mathbf{n} \times \mathbf{v}\) (ce dernier est bien perpendiculaire à la fois à \(\mathbf{n}\) et à \(\mathbf{v}_\perp\), et de même norme que \(\mathbf{v}_\perp\)). La rotation de \(\mathbf{v}_\perp\) d’un angle \(\theta\) dans ce plan donne :
\[ \mathbf{v}'_\perp = \cos(\theta) \, \mathbf{v}_\perp + \sin(\theta) \, \mathbf{n} \times \mathbf{v} \]
En recombinant \(\mathbf{v}' = \mathbf{v}_\parallel + \mathbf{v}'_\perp\) et en substituant les expressions de \(\mathbf{v}_\parallel\) et \(\mathbf{v}_\perp\) :
\[ \mathbf{v}' = \cos(\theta) \, \mathbf{v} + \sin(\theta) \, \mathbf{n} \times \mathbf{v} + (1 - \cos(\theta)) \, (\mathbf{v} \cdot \mathbf{n}) \, \mathbf{n} \]
C’est la formule de Rodrigues.

On peut vérifier les cas limites : pour \(\theta = 0\), on obtient \(\mathbf{v}' = \mathbf{v}\) (pas de rotation) ; pour \(\theta = \pi/2\), on obtient \(\mathbf{v}' = \sin(\pi/2) \, \mathbf{n} \times \mathbf{v} + (1 - \cos(\pi/2))(\mathbf{v} \cdot \mathbf{n}) \mathbf{n} = \mathbf{n} \times \mathbf{v} + (\mathbf{v} \cdot \mathbf{n}) \mathbf{n}\), c’est-à-dire un quart de tour de la composante perpendiculaire (remplacement par le vecteur orthogonal dans le plan).
La formule de Rodrigues exprime \(\mathbf{v}'\) comme une fonction linéaire de \(\mathbf{v}\) (chaque terme — produit scalaire, produit vectoriel — est linéaire en \(\mathbf{v}\)). Il existe donc une matrice \(R\) telle que \(\mathbf{v}' = R \, \mathbf{v}\). Pour l’obtenir, on réécrit chaque opération sous forme matricielle.
Le produit vectoriel \(\mathbf{n} \times \mathbf{v}\) correspond à la multiplication par la matrice antisymétrique :
\[ K = \begin{pmatrix} 0 & -n_z & n_y \\ n_z & 0 & -n_x \\ -n_y & n_x & 0 \end{pmatrix} \]
telle que \(K \, \mathbf{v} = \mathbf{n} \times \mathbf{v}\) pour tout \(\mathbf{v}\). Le terme \((\mathbf{v} \cdot \mathbf{n}) \, \mathbf{n}\) correspond à la projection sur \(\mathbf{n}\), qui s’écrit \(\mathbf{n} \mathbf{n}^T \mathbf{v}\). En utilisant l’identité \(\mathbf{n} \mathbf{n}^T = I + K^2\) (valable lorsque \(\|\mathbf{n}\| = 1\), car \(K^2 = \mathbf{n}\mathbf{n}^T - I\)), on peut réécrire la formule de Rodrigues entièrement en termes de \(K\) :
\[ R(\mathbf{n}, \theta) = \cos(\theta) \, I + \sin(\theta) \, K + (1 - \cos(\theta)) \, (I + K^2) \]
ce qui se simplifie en :
\[ R(\mathbf{n}, \theta) = I + \sin(\theta) \, K + (1 - \cos(\theta)) \, K^2 \]
En développant les produits matriciels, on obtient explicitement :
\[ R = \begin{pmatrix} \cos\theta + n_x^2 (1 - \cos\theta) & n_x n_y (1 - \cos\theta) - n_z \sin\theta & n_x n_z (1 - \cos\theta) + n_y \sin\theta \\ n_x n_y (1 - \cos\theta) + n_z \sin\theta & \cos\theta + n_y^2 (1 - \cos\theta) & n_y n_z (1 - \cos\theta) - n_x \sin\theta \\ n_x n_z (1 - \cos\theta) - n_y \sin\theta & n_y n_z (1 - \cos\theta) + n_x \sin\theta & \cos\theta + n_z^2 (1 - \cos\theta) \end{pmatrix} \]
On peut vérifier que cette matrice est bien orthogonale et de déterminant 1. Par exemple, pour \(\mathbf{n} = (0, 0, 1)\) (rotation autour de \(z\)), on retrouve \(R_z(\theta)\) définie plus haut.
Les quaternions sont une généralisation des nombres complexes à quatre dimensions. Là où un nombre complexe \(a + b \, \mathbf{i}\) possède une unité imaginaire \(\mathbf{i}\) (avec \(\mathbf{i}^2 = -1\)), un quaternion possède trois unités imaginaires \(\mathbf{i}\), \(\mathbf{j}\), \(\mathbf{k}\) :
\[ q = x \, \mathbf{i} + y \, \mathbf{j} + z \, \mathbf{k} + w \]
avec la notation courte \(q = (x, y, z, w)\). La partie réelle est \(w\), la partie imaginaire (ou quaternion pur) est le triplet \((x, y, z)\). On note aussi \(q = (\mathbf{s}, w)\) avec \(\mathbf{s} = (x, y, z)\).
Les bases imaginaires satisfont les règles de multiplication suivantes :
\[ \mathbf{i}^2 = \mathbf{j}^2 = \mathbf{k}^2 = -1, \quad \mathbf{i}\mathbf{j} = \mathbf{k}, \quad \mathbf{j}\mathbf{k} = \mathbf{i}, \quad \mathbf{k}\mathbf{i} = \mathbf{j} \]
et les produits dans l’ordre inverse changent de signe : \(\mathbf{j}\mathbf{i} = -\mathbf{k}\), \(\mathbf{k}\mathbf{j} = -\mathbf{i}\), \(\mathbf{i}\mathbf{k} = -\mathbf{j}\). On a aussi la relation \(\mathbf{i}\mathbf{j}\mathbf{k} = -1\). La ressemblance avec les règles du produit vectoriel n’est pas un hasard — le produit vectoriel peut se voir comme la partie imaginaire du produit de deux quaternions purs.
Attention : ne pas confondre la notation \((x, y, z, w)\) d’un quaternion avec un vecteur 4D en coordonnées homogènes. Les quaternions vivent dans un espace algébrique muni de son propre produit, très différent de \(\mathbb{R}^4\).
Les opérations sur les quaternions sont analogues à celles des nombres complexes :
Le produit de deux quaternions se calcule en développant le produit formel et en appliquant les règles de multiplication des bases. En notant \(q_i = (\mathbf{s}_i, w_i)\) avec \(\mathbf{s}_i = (x_i, y_i, z_i)\), on obtient la formule compacte :
\[ q_1 \, q_2 = (\mathbf{s}_1 w_2 + \mathbf{s}_2 w_1 + \mathbf{s}_1 \times \mathbf{s}_2, \;\; w_1 w_2 - \mathbf{s}_1 \cdot \mathbf{s}_2) \]
La partie imaginaire du produit combine un produit vectoriel (\(\mathbf{s}_1 \times \mathbf{s}_2\)) et des termes croisés scalaire-vecteur, tandis que la partie réelle combine un produit scalaire et un produit de réels. On peut aussi écrire le produit composante par composante :
\[ q_1 \, q_2 = \begin{pmatrix} x_1 w_2 + w_1 x_2 + y_1 z_2 - z_1 y_2 \\ y_1 w_2 + w_1 y_2 + z_1 x_2 - x_1 z_2 \\ z_1 w_2 + w_1 z_2 + x_1 y_2 - y_1 x_2 \\ w_1 w_2 - x_1 x_2 - y_1 y_2 - z_1 z_2 \end{pmatrix} \]
Le produit de quaternions est associatif (\(q_1 (q_2 q_3) = (q_1 q_2) q_3\)) mais non commutatif (\(q_1 q_2 \neq q_2 q_1\)), comme le produit matriciel. La non-commutativité reflète le fait que les rotations 3D ne commutent pas : tourner d’abord autour de \(x\) puis autour de \(y\) ne donne pas le même résultat que l’ordre inverse.
Une propriété importante du produit est que le conjugué d’un produit s’inverse : \((q_1 q_2)^* = q_2^* q_1^*\) (comme pour la transposée d’un produit de matrices). De plus, le produit de deux quaternions unitaires est unitaire : \(\|q_1 q_2\| = \|q_1\| \cdot \|q_2\|\).
Le lien entre quaternions et rotations repose sur une construction qui rappelle les nombres complexes. En 2D, un nombre complexe unitaire \(e^{i\theta} = \cos\theta + i \sin\theta\) représente une rotation d’angle \(\theta\), et la rotation d’un vecteur \(z\) s’obtient par le produit \(z' = e^{i\theta} \cdot z\). En 3D, le mécanisme est similaire mais nécessite un produit “sandwich” à cause de la non-commutativité.
Soit \(q = (\mathbf{s}, w)\) un quaternion unitaire (\(\|q\| = 1\)), et \(\mathbf{v}\) un vecteur 3D assimilé au quaternion pur \(q_v = (\mathbf{v}, 0)\) (partie réelle nulle). Alors :
\[ q_{v'} = q \, q_v \, q^* = (\mathbf{v}', 0) \]
est un quaternion pur (la partie réelle est bien nulle — ce n’est pas évident a priori), et \(\mathbf{v}'\) est le vecteur \(\mathbf{v}\) après rotation d’angle \(2 \arccos(w)\) autour de l’axe \(\mathbf{n} = \mathbf{s} / \|\mathbf{s}\|\).
Le produit “sandwich” \(q \, q_v \, q^*\) (multiplication à gauche par \(q\) et à droite par \(q^*\)) est nécessaire pour que le résultat soit un quaternion pur : le simple produit \(q \, q_v\) aurait une partie réelle non nulle et ne correspondrait pas à un vecteur 3D.
Démonstration. En développant le triple produit à l’aide de la formule du produit de quaternions :
\[ \mathcal{R}_q(\mathbf{v}) = q \, q_v \, q^* = ((w^2 - \|\mathbf{s}\|^2) \, \mathbf{v} + 2(\mathbf{s} \cdot \mathbf{v}) \, \mathbf{s} + 2w \, \mathbf{s} \times \mathbf{v}, \;\; 0) \]
Comme \(\|q\| = 1\), on peut paramétrer \(q = (\mathbf{n} \sin\phi, \cos\phi)\) avec \(\|\mathbf{n}\| = 1\). En substituant \(\mathbf{s} = \mathbf{n} \sin\phi\) et \(w = \cos\phi\) :
\[ \mathcal{R}_q(\mathbf{v}) = \underbrace{(\cos^2\phi - \sin^2\phi)}_{\cos(2\phi)} \mathbf{v} + \underbrace{2 \sin^2\phi}_{1 - \cos(2\phi)} (\mathbf{n} \cdot \mathbf{v}) \, \mathbf{n} + \underbrace{2 \cos\phi \sin\phi}_{\sin(2\phi)} \, \mathbf{n} \times \mathbf{v} \]
On reconnaît exactement la formule de Rodrigues pour l’axe \(\mathbf{n}\) et l’angle \(2\phi\). Le facteur 2 explique le demi-angle dans la correspondance :
Le quaternion unitaire \(q = (\mathbf{n} \sin(\theta/2), \cos(\theta/2))\) représente la rotation d’angle \(\theta\) autour de l’axe \(\mathbf{n}\).
Ce demi-angle a une conséquence topologique importante : une rotation de \(2\pi\) (un tour complet) correspond au quaternion \((\mathbf{n} \sin(\pi), \cos(\pi)) = (0, 0, 0, -1) = -1\), et il faut un angle de \(4\pi\) pour revenir au quaternion \(+1\). L’espace des quaternions unitaires constitue donc un double recouvrement de \(SO(3)\) : deux quaternions \(+q\) et \(-q\) représentent la même rotation (nous y reviendrons dans la section sur l’interpolation).
Soient deux rotations associées aux quaternions unitaires \(q_1\) et \(q_2\). Le produit \(q_1 \, q_2\) représente la composition \(R_1 \circ R_2\).
La démonstration est directe :
\[ \mathcal{R}_{q_1 q_2}(\mathbf{v}) = (q_1 q_2) \, \mathbf{v} \, (q_1 q_2)^* = q_1 (q_2 \, \mathbf{v} \, q_2^*) q_1^* = q_1 \, \mathcal{R}_{q_2}(\mathbf{v}) \, q_1^* = \mathcal{R}_{q_1} \circ \mathcal{R}_{q_2}(\mathbf{v}) \]
en utilisant la propriété \((q_1 q_2)^* = q_2^* q_1^*\).
Le quaternion unitaire \(q = (x, y, z, w)\) correspond à la matrice de rotation :
\[ R = \begin{pmatrix} 1 - 2(y^2 + z^2) & 2(xy - wz) & 2(xz + wy) \\ 2(xy + wz) & 1 - 2(x^2 + z^2) & 2(yz - wx) \\ 2(xz - wy) & 2(yz + wx) & 1 - 2(x^2 + y^2) \end{pmatrix} \]
Inversement, à partir d’une matrice de rotation \(M\), on peut extraire le quaternion correspondant. Lorsque la trace de \(M\) est positive (\(1 + M_{xx} + M_{yy} + M_{zz} > 0\)), on utilise :
\[ q = \left(\frac{M_{zy} - M_{yz}}{2r}, \; \frac{M_{xz} - M_{zx}}{2r}, \; \frac{M_{yx} - M_{xy}}{2r}, \; \frac{r}{2}\right), \quad r = \sqrt{1 + M_{xx} + M_{yy} + M_{zz}} \]
Lorsque la trace est proche de zéro ou négative (ce qui arrive pour des rotations proches de \(\pi\)), cette formule devient numériquement instable (\(r \to 0\)). En pratique, on utilise une version par cas qui choisit la composante dominante de la diagonale pour éviter les divisions par des valeurs proches de zéro.
| Représentation | Avantages | Inconvénients |
|---|---|---|
| Matrice | Calcul direct, composition simple | Paramètres non explicites (9 coeff. pour 3 DOF) |
| Angles d’Euler | Paramètres compréhensibles, interaction directe | Gimbal lock, interpolation inadaptée |
| Axe-angle | Concis, intuitif | Pas de composition simple |
| Quaternion | Composition, interpolation, pas de gimbal lock | Composantes moins intuitives |
Le tableau suivant donne une indication comparative du coût des opérations courantes selon la représentation ; les performances réelles dépendent de l’implémentation et du matériel :
| Opération | Matrice | Quaternion |
|---|---|---|
| Stockage | 9 flottants | 4 flottants |
| Rotation d’un vecteur | rapide | modéré |
| Composition | modéré | rapide |
| Inversion | négligeable (transposition) | négligeable (conjugué) |
| Interpolation | coûteux (exp/log matriciel) | rapide (SLERP) |
La rotation d’un vecteur est plus rapide par matrice, mais la composition de rotations et l’interpolation sont plus efficaces en quaternion. En pratique, on stocke et interpole les orientations en quaternions, puis on convertit en matrice au moment du rendu (le GPU attend des matrices).
L’interpolation de rotations intervient dès qu’on souhaite animer une orientation : transition entre deux poses d’un personnage, rotation progressive de la caméra, interpolation entre les key-frames d’une animation. Étant données deux rotations \(r_1\) et \(r_2\), on cherche une rotation \(r(t)\) variant continûment avec \(t \in [0, 1]\) telle que \(r(0) = r_1\) et \(r(1) = r_2\).
La difficulté est que les rotations ne vivent pas dans un espace vectoriel : le résultat intermédiaire doit être une rotation valide à chaque instant \(t\), sans scaling ni shearing parasite. Toutes les représentations ne se prêtent pas également à l’interpolation :
L’approche la plus simple consiste à interpoler linéairement les quaternions dans \(\mathbb{R}^4\), puis à renormaliser le résultat pour revenir sur la sphère unitaire :
\[ q(t) = \frac{(1 - t) \, q_1 + t \, q_2}{\|(1 - t) \, q_1 + t \, q_2\|} \]
Géométriquement, la combinaison linéaire \((1-t) q_1 + t q_2\) produit un point à l’intérieur de la sphère (sur la corde reliant \(q_1\) à \(q_2\)), et la normalisation le reprojette sur la sphère. Le chemin résultant sur la sphère suit bien le grand cercle (le plus court chemin), mais la vitesse le long de ce chemin n’est pas constante : la paramétrisation est plus rapide aux extrémités (\(t\) proche de 0 ou 1) et plus lente au milieu. En effet, la reprojection radiale “concentre” les points vers le milieu de l’arc.

Le LERP peut être généralisé à des courbes paramétriques (splines de quaternions, etc.), ce qui en fait un outil utile pour les animations avec plus de deux key-frames. En revanche, la vitesse angulaire non constante peut poser problème pour des applications nécessitant un mouvement régulier.
Pour obtenir une vitesse angulaire constante (la rotation progresse uniformément avec \(t\)), on utilise l’interpolation sphérique linéaire (SLERP). L’idée est d’interpoler directement sur la sphère plutôt que de passer par une corde puis reprojeter.
Soit \(\Omega\) l’angle entre \(q_1\) et \(q_2\) dans l’espace 4D, défini par \(\cos(\Omega) = q_1 \cdot q_2\) (produit scalaire des 4 composantes) :
\[ q(t) = \frac{\sin((1 - t) \, \Omega)}{\sin(\Omega)} \, q_1 + \frac{\sin(t \, \Omega)}{\sin(\Omega)} \, q_2 \]

Démonstration. On construit un repère orthonormé dans le plan \((q_1, q_2)\), avec \(q_1\) comme premier vecteur et \(q_1^\perp = \frac{q_2 - \cos(\Omega) \, q_1}{\sin(\Omega)}\) comme second. Le vecteur à l’angle \(\theta = \Omega \, t\) de \(q_1\) s’écrit \(q(t) = q_1 \cos(\Omega t) + q_1^\perp \sin(\Omega t)\). En substituant \(q_1^\perp\) et en utilisant l’identité \(\sin(\Omega) \cos(\Omega t) - \cos(\Omega) \sin(\Omega t) = \sin((1-t)\Omega)\), on retrouve la formule du SLERP. On vérifie que \(q(0) = q_1\), \(q(1) = q_2\), et \(\|q(t)\| = 1\) pour tout \(t\).
Avantages du SLERP : chemin le plus court sur la sphère, vitesse angulaire constante, résultat toujours unitaire.
Inconvénient : ne se généralise pas directement à l’interpolation entre plus de deux quaternions. Pour des animations avec \(N\) key-frames, on utilise des méthodes dérivées, souvent basées sur le LERP normalisé (nLERP) qui, bien que n’ayant pas une vitesse angulaire constante, se prête plus facilement à la construction de splines.
Cas dégénéré : lorsque \(\Omega\) est très petit (\(q_1 \approx q_2\)), le dénominateur \(\sin(\Omega)\) tend vers 0 et la formule devient numériquement instable. En pratique, on bascule sur le LERP (avec renormalisation) lorsque \(\Omega\) est inférieur à un seuil (typiquement \(10^{-4}\)).
Comme mentionné précédemment, les quaternions \(+q\) et \(-q\) représentent la même rotation (puisque \(\mathbf{n} \to -\mathbf{n}\) et \(\theta \to 2\pi - \theta\), le produit “sandwich” reste identique). Cependant, sur la sphère \(S^3\), \(+q\) et \(-q\) sont deux points antipodaux, et ils correspondent à des chemins d’interpolation différents.
L’interpolation SLERP entre \(q_1\) et \(q_2\) suit le plus court arc de grand cercle sur la sphère. Mais il existe deux arcs possibles entre \(q_1\) et \(q_2\) (le court et le long), et l’arc entre \(q_1\) et \(-q_2\) est le complémentaire de celui entre \(q_1\) et \(q_2\). Concrètement :
En pratique, si on oublie cette vérification, l’objet peut tourner “par le chemin long” — une rotation de 350° au lieu de 10° — ce qui produit un mouvement visuellement aberrant. On corrige en inversant \(q_2\) lorsque nécessaire :
if (dot(q1, q2) < 0)
q2 = -q2;
q_t = slerp(q1, q2, t);Montrons que la vitesse constante sur la sphère des quaternions implique une vitesse angulaire constante en 3D.
Soit \(q(t)\) un quaternion unitaire dépendant du temps, et \(R(t)\) la rotation 3D associée. La vitesse angulaire \(\boldsymbol{\omega}(t) \in \mathbb{R}^3\) est définie par la relation \(\dot{R} = [\boldsymbol{\omega}]_\times R\), où \([\boldsymbol{\omega}]_\times\) est la matrice antisymétrique associée au produit vectoriel par \(\boldsymbol{\omega}\). En termes de quaternions, cette relation se traduit par :
\[ \dot{q} = \frac{1}{2} \, \boldsymbol{\omega}_q \, q \]
où \(\boldsymbol{\omega}_q = ({\omega_x}, {\omega_y}, {\omega_z}, 0)\) est le quaternion pur associé au vecteur \(\boldsymbol{\omega}\). En inversant cette relation (\(q\) est unitaire, donc \(q^{-1} = q^*\)) :
\[ \boldsymbol{\omega}_q = 2 \, \dot{q} \, q^* \]
La norme de la vitesse angulaire est donc \(\|\boldsymbol{\omega}\| = 2 \|\dot{q}\|\) (car \(\|q^*\| = 1\) et le produit de quaternions préserve les normes). Ce facteur 2 provient du demi-angle dans la correspondance quaternion-rotation.
Pour le SLERP, \(q(t)\) parcourt un arc de grand cercle sur \(S^3\) à vitesse \(\|\dot{q}\|\) constante (par construction de l’interpolation sphérique linéaire). La relation \(\|\boldsymbol{\omega}\| = 2\|\dot{q}\|\) montre alors que la vitesse angulaire 3D est elle aussi constante. Concrètement, la distance géodésique \(\Omega\) sur \(S^3\) entre \(q_1\) et \(q_2\) est liée à l’angle de rotation 3D \(\theta\) entre \(R_1\) et \(R_2\) par \(\Omega = \theta / 2\), et le SLERP parcourt cette distance uniformément.
En pratique, un objet 3D est caractérisé par une orientation \(r\) (rotation) et une position \(\mathbf{p}\) (translation). Pour interpoler entre deux configurations \((r_1, \mathbf{p}_1)\) et \((r_2, \mathbf{p}_2)\) — par exemple pour animer un objet qui se déplace en tournant — on interpole les deux composantes séparément :
La combinaison des deux donne un mouvement rigide (sans déformation) qui varie régulièrement entre les deux configurations. C’est l’interpolation standard utilisée dans les moteurs d’animation pour les key-frames de position et d’orientation.
Lorsque les transformations incluent du scaling ou de la déformation (shearing) en plus de la rotation et de la translation, une simple interpolation SLERP + linéaire ne suffit plus. Il faut d’abord séparer les différentes composantes de la transformation pour les interpoler chacune de manière appropriée.
L’outil mathématique clé est la décomposition polaire : toute matrice \(3 \times 3\) inversible se décompose en \(M = R \, D\), où \(R\) est une matrice de rotation (\(R \in SO(3)\)) et \(D\) est une matrice semi-définie positive symétrique (qui encode le scaling et le shearing). Cette décomposition est l’analogue matriciel de l’écriture d’un nombre complexe en forme polaire \(z = r \, e^{i\theta}\). Elle peut être calculée par SVD (\(M = U \Sigma V^T\), alors \(R = U V^T\) et \(D = V \Sigma V^T\)) ou par le schéma itératif \(R_{i+1} = \frac{1}{2}(R_i + (R_i^{-1})^T)\) en partant de \(R_0 = M\).
L’interpolation linéaire de \(M\) sans décomposition préalable produit des artefacts : un objet qui devrait tourner proprement se déforme temporairement puis revient à sa forme initiale. La décomposition polaire permet d’interpoler chaque composante avec la méthode adaptée.
L’algorithme complet pour interpoler entre deux matrices \(4 \times 4\) générales \(M_1\) et \(M_2\) est :
Soit une transformation affine \(M\) appliquée aux positions d’un objet : \(\mathbf{p}' = M \mathbf{p}\). Les vecteurs tangents à la surface, définis comme des différences de positions voisines, se transforment par la même matrice : \(\mathbf{t}' = M \mathbf{t}\). La question est de déterminer comment se transforment les normales \(\mathbf{n}\) sous l’action de \(M\).
Pour une rotation \(R\), la normale se transforme par \(\mathbf{n}' = R \mathbf{n}\) : l’orthogonalité est préservée car \(R\) conserve les angles. Pour un scaling uniforme \(sI\), la direction de la normale est inchangée (seule sa norme est affectée, corrigée par renormalisation). Dans ces deux cas, appliquer \(M\) directement aux normales produit un résultat correct (à renormalisation près).
Le problème apparaît en présence de scaling non uniforme ou de shearing. Considérons un plan horizontal avec une normale verticale \(\mathbf{n} = (0, 1, 0)\), et appliquons un étirement horizontal \(S = \text{diag}(2, 1, 1)\) (doublement de la coordonnée \(x\)). La surface s’étire horizontalement, mais la normale reste verticale — elle ne devrait pas changer. Or \(S \mathbf{n} = (0, 1, 0) = \mathbf{n}\), ce qui est correct dans ce cas. Maintenant, prenons un plan incliné à 45° avec \(\mathbf{n} = (1, 1, 0)/\sqrt{2}\). Après l’étirement horizontal, le plan est “aplati” et sa normale devrait s’incliner vers la verticale. Mais \(S \mathbf{n} = (2, 1, 0)/\sqrt{5}\), qui s’incline au contraire vers l’horizontale — le résultat est faux. La normale transformée par \(M\) n’est plus perpendiculaire à la surface transformée.
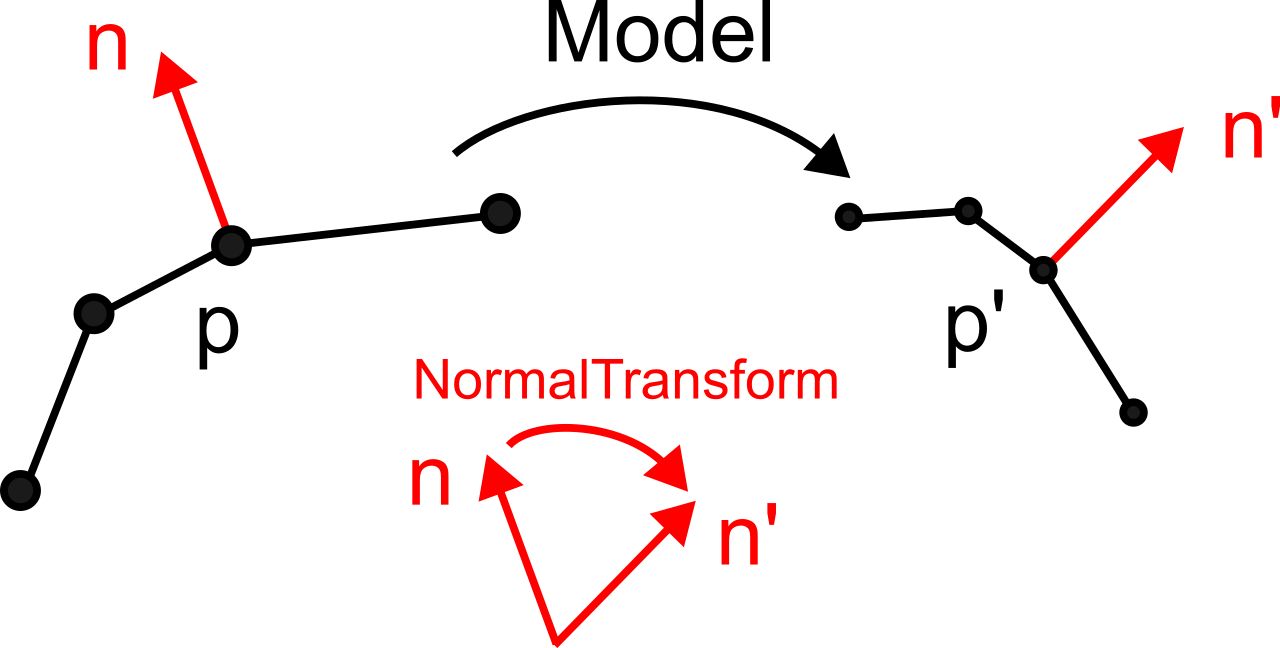
La propriété fondamentale d’une normale est son orthogonalité aux tangentes de la surface. Soit \(\mathbf{t}\) un vecteur tangent à la surface en un point \(\mathbf{p}\). Avant transformation : \(\mathbf{n} \cdot \mathbf{t} = 0\). Après transformation, les tangentes se transforment par \(\mathbf{t}' = M \mathbf{t}\), et on cherche la matrice \(N\) telle que les normales transformées \(\mathbf{n}' = N \mathbf{n}\) satisfassent \(\mathbf{n}' \cdot \mathbf{t}' = 0\) pour tout tangent \(\mathbf{t}\).
En développant la condition d’orthogonalité après transformation :
\[ (N \mathbf{n})^T (M \mathbf{t}) = \mathbf{n}^T N^T M \mathbf{t} = 0 \]
On sait que \(\mathbf{n}^T \mathbf{t} = 0\). Une condition suffisante (et la plus simple) pour que \(\mathbf{n}^T (N^T M) \mathbf{t} = 0\) pour tout \(\mathbf{t}\) orthogonal à \(\mathbf{n}\) est que \(N^T M = I\), c’est-à-dire :
\[ N = (M^{-1})^T \]
La matrice de transformation des normales est la transposée de l’inverse de la matrice de transformation des positions (parfois notée \(M^{-T}\)).
En GLSL, on travaille avec la sous-matrice \(3 \times 3\) de la matrice Model (qui contient la rotation et le scaling, sans la translation — les normales sont des directions, pas des positions) :
mat3 normalMatrix = transpose(inverse(mat3(Model)));
vec3 n = normalize(normalMatrix * vertex_normal);L’appel mat3(Model) extrait la sous-matrice \(3 \times 3\) supérieure gauche. La
renormalisation finale est nécessaire car \((M^{-1})^T\) ne préserve pas la norme en
général.
Lorsque \(M\) est une rotation pure (ou une transformation rigide : rotation + translation), on a \(M^{-1} = M^T\) (car \(R^{-1} = R^T\) pour les rotations), donc \(N = (M^{-1})^T = M\). La transformation des normales coïncide avec celle des positions : les normales se transforment par la même matrice, sans traitement particulier.
Lorsque \(M\) contient un scaling uniforme \(s\) en plus de la rotation (\(M = sR\)), on obtient \(N = (s^{-1} R^{-1})^T = s^{-1} R\). Le facteur \(s^{-1}\) modifie la norme de la normale, mais pas sa direction. Après renormalisation, le résultat est identique à \(R \mathbf{n}\).
Le cas non trivial apparaît uniquement en présence de scaling non uniforme (facteurs différents selon les axes) ou de shearing. C’est dans ces cas que l’utilisation de \((M^{-1})^T\) est indispensable pour obtenir un éclairage correct.
Note de performance : le calcul de
transpose(inverse(Model)) à chaque fragment est coûteux. En
pratique, cette matrice est pré-calculée côté CPU et envoyée au shader
comme un uniform, au même titre que la matrice Model elle-même.
L’ordre dans lequel les transformations sont appliquées est fondamental et constitue une source fréquente d’erreurs en programmation graphique. Pour une rotation \(R\) et une translation \(\mathbf{t}\), on a en général :
\[ T \, R \neq R \, T \]
Les matrices de transformation (en coordonnées homogènes \(4 \times 4\)) s’appliquent de droite à gauche : dans le produit \(M \, \mathbf{p} = (A \, B) \, \mathbf{p}\), c’est \(B\) qui est appliqué en premier au point \(\mathbf{p}\), puis \(A\) au résultat. Cet ordre “inversé” par rapport à la lecture est une convention mathématique standard, mais il faut s’y habituer.
Détaillons les deux cas sur un exemple concret.
Cas 1 : \(M_1 = T \, R\) (d’abord rotation, puis translation)
\[ M_1 = \begin{pmatrix} I & \mathbf{t} \\ 0 & 1 \end{pmatrix} \begin{pmatrix} R & 0 \\ 0 & 1 \end{pmatrix} = \begin{pmatrix} R & \mathbf{t} \\ 0 & 1 \end{pmatrix} \]
L’objet est d’abord tourné autour de l’origine (ses sommets sont multipliés par \(R\)), puis l’ensemble est déplacé de \(\mathbf{t}\). Le résultat est un objet tourné, dont le centre est à la position \(\mathbf{t}\). C’est le cas typique du placement d’un objet dans la scène : on l’oriente d’abord (rotation), puis on le positionne (translation).
Cas 2 : \(M_2 = R \, T\) (d’abord translation, puis rotation)
\[ M_2 = \begin{pmatrix} R & 0 \\ 0 & 1 \end{pmatrix} \begin{pmatrix} I & \mathbf{t} \\ 0 & 1 \end{pmatrix} = \begin{pmatrix} R & R \, \mathbf{t} \\ 0 & 1 \end{pmatrix} \]
L’objet est d’abord déplacé de \(\mathbf{t}\) (éloigné de l’origine), puis l’ensemble est tourné autour de l’origine. La rotation s’appliquant autour de l’origine, l’objet décrit un arc de cercle. La translation effective n’est plus \(\mathbf{t}\) mais \(R \, \mathbf{t}\) : le vecteur de translation lui-même a été tourné. C’est le cas typique de l’orbite : un objet éloigné de l’origine qui tourne autour d’elle.


À gauche : $M_1 = T \, R$ (rotation puis translation). À droite : $M_2 = R \, T$ (translation puis rotation autour de l'origine).
La différence entre les deux cas est frappante : \(M_1\) produit un objet tourné sur place puis translaté, tandis que \(M_2\) produit un objet qui orbite autour de l’origine. La confusion entre ces deux cas est l’une des erreurs les plus courantes en programmation 3D.
Attention : certaines bibliothèques (ancien OpenGL
en mode fixed pipeline, Three.js) utilisent une convention de
multiplication matricielle transposée par rapport à la
convention mathématique standard. Dans ces bibliothèques, les
transformations s’appliquent de gauche à droite dans le code. Par
exemple, en ancien OpenGL, le code
glTranslate(); glRotate(); applique d’abord la translation,
puis la rotation — ce qui correspond à \(M_2 =
R \, T\) dans notre convention. Il faut consulter la
documentation de chaque bibliothèque pour connaître la convention
utilisée.
Les rotations exprimées par des matrices \(R\) s’effectuent toujours autour de l’origine. Pour appliquer une rotation autour d’un point arbitraire \(\mathbf{p}_0\), le schéma classique consiste en trois étapes : (1) translater pour amener \(\mathbf{p}_0\) à l’origine, (2) effectuer la rotation, (3) retranslater pour remettre \(\mathbf{p}_0\) à sa position :
\[ M = T(\mathbf{p}_0) \, R \, T(-\mathbf{p}_0) \]
En développant le produit des trois matrices \(4 \times 4\) :
\[ M = \begin{pmatrix} I & \mathbf{p}_0 \\ 0 & 1 \end{pmatrix} \begin{pmatrix} R & 0 \\ 0 & 1 \end{pmatrix} \begin{pmatrix} I & -\mathbf{p}_0 \\ 0 & 1 \end{pmatrix} = \begin{pmatrix} R & \mathbf{p}_0 - R \, \mathbf{p}_0 \\ 0 & 1 \end{pmatrix} \]
On peut vérifier que \(M \, \mathbf{p}_0 = R \, \mathbf{p}_0 + \mathbf{p}_0 - R \, \mathbf{p}_0 = \mathbf{p}_0\) : le point \(\mathbf{p}_0\) est bien fixe, comme attendu.
Ce schéma est omniprésent en pratique. Par exemple, pour faire tourner un maillage autour de son barycentre \(\bar{\mathbf{p}} = \frac{1}{N} \sum_{i=1}^{N} \mathbf{p}_i\), on utilise \(M = T(\bar{\mathbf{p}}) \, R \, T(-\bar{\mathbf{p}})\). Pour faire tourner un bras articulé autour de l’épaule, on translate d’abord l’épaule à l’origine, on applique la rotation, puis on retranslate. Ce motif “translate-rotate-untranslate” apparaît à chaque articulation d’un squelette d’animation.
Une transformation affine paramétrée par un scaling uniforme \(s\), une rotation \(R\) et une translation \(\mathbf{t}\) s’écrit sous forme de matrice bloc \(4 \times 4\) :
\[ M = T \, R \, S = \begin{pmatrix} s \, R & \mathbf{t} \\ 0 & 1 \end{pmatrix} \]
Son inverse est \((AB)^{-1} = B^{-1} A^{-1}\), donc \(M^{-1} = S^{-1} \, R^{-1} \, T^{-1}\). En développant :
\[ M^{-1} = \begin{pmatrix} \frac{1}{s} R^T & -\frac{1}{s} R^T \mathbf{t} \\ 0 & 1 \end{pmatrix} \]
Chaque composante s’inverse simplement : la translation en \(-\mathbf{t}\), la rotation en \(R^T\), le scale en \(1/s\). Mais il faut appliquer ces inverses dans l’ordre opposé à celui de la composition originale, ce qui explique le terme \(-\frac{1}{s} R^T \mathbf{t}\) (et non simplement \(-\mathbf{t}\)) dans le bloc de translation.
En informatique graphique, les objets d’une scène ne sont presque jamais indépendants les uns des autres. Un personnage a des bras rattachés au torse, un véhicule a des roues rattachées au châssis, un système solaire a des lunes qui orbitent autour de planètes qui orbitent autour d’une étoile. Dans chacun de ces cas, le mouvement d’un objet enfant est défini relativement à un objet parent : la main bouge par rapport à l’avant-bras, qui bouge par rapport au bras, qui bouge par rapport au torse.
Cette organisation hiérarchique se formalise par une hiérarchie de repères (ou frame hierarchy). Chaque objet possède une transformation locale \(M_{\text{local}}\) qui décrit sa position et son orientation par rapport à son parent. La transformation globale (ou world transform) qui place l’objet dans le repère mondial est obtenue en composant toutes les transformations locales depuis la racine de la hiérarchie :
\[ M_{\text{global}} = M_{\text{parent}}^{\text{global}} \; M_{\text{local}} \]
En développant récursivement :
\[ M_{\text{global}}^{(i)} = M_{\text{local}}^{(0)} \; M_{\text{local}}^{(1)} \; \ldots \; M_{\text{local}}^{(i)} \]
où \(M_{\text{local}}^{(0)}\) est la transformation de la racine (souvent l’identité), \(M_{\text{local}}^{(1)}\) celle de son enfant, etc. Les matrices se composent de gauche à droite dans la hiérarchie, ce qui correspond à l’application de droite à gauche sur les points : un point \(\mathbf{p}\) de l’objet \((i)\), exprimé dans le repère local de \((i)\), est transformé d’abord par \(M_{\text{local}}^{(i)}\), puis par \(M_{\text{local}}^{(i-1)}\), etc.
Chaque transformation locale est une transformation rigide (rotation + translation), représentée en coordonnées homogènes par une matrice \(4 \times 4\) de la forme :
\[ M = \begin{pmatrix} R & \mathbf{t} \\ 0 & 1 \end{pmatrix} \]
où \(R \in SO(3)\) est la matrice de rotation \(3 \times 3\) et \(\mathbf{t} \in \mathbb{R}^3\) le vecteur de translation. La composition de deux telles transformations se calcule par blocs :
\[ M_{\text{global}} = M_{\text{parent}} \; M_{\text{local}} = \begin{pmatrix} R_p & \mathbf{t}_p \\ 0 & 1 \end{pmatrix} \begin{pmatrix} R_l & \mathbf{t}_l \\ 0 & 1 \end{pmatrix} = \begin{pmatrix} R_p R_l & R_p \mathbf{t}_l + \mathbf{t}_p \\ 0 & 1 \end{pmatrix} \]
La rotation globale est donc le produit des rotations \(R_g = R_p R_l\), et la translation globale est \(\mathbf{t}_g = R_p \mathbf{t}_l + \mathbf{t}_p\). Le terme \(R_p \mathbf{t}_l\) traduit le fait que la translation locale de l’enfant est exprimée dans le repère du parent — elle doit être tournée par la rotation du parent avant d’être ajoutée à la translation du parent.
Si l’on inclut un scaling uniforme \(s\) (ce qui est courant dans les graphes de scène), la transformation locale prend la forme :
\[ M = \begin{pmatrix} s R & \mathbf{t} \\ 0 & 1 \end{pmatrix} \]
et la composition donne :
\[ M_{\text{global}} = \begin{pmatrix} s_p R_p \; s_l R_l & s_p R_p \mathbf{t}_l + \mathbf{t}_p \\ 0 & 1 \end{pmatrix} = \begin{pmatrix} s_p s_l \; R_p R_l & s_p R_p \mathbf{t}_l + \mathbf{t}_p \\ 0 & 1 \end{pmatrix} \]
Le scaling global est le produit \(s_g = s_p \, s_l\), la rotation globale reste \(R_g = R_p R_l\), et la translation locale est à la fois tournée et mise à l’échelle par le parent : \(\mathbf{t}_g = s_p R_p \mathbf{t}_l + \mathbf{t}_p\).
Les formules ci-dessus s’appliquent aux transformations rigides et au scaling uniforme. En présence de scaling non uniforme ou de shearing, la décomposition en rotation / translation / échelle devient plus délicate et la propagation hiérarchique ne se réduit plus à ces formules simples.
Propriété fondamentale : lorsqu’on modifie la transformation locale d’un nœud, tous ses descendants sont automatiquement affectés. Si le torse tourne de 30°, les bras, avant-bras, mains et doigts suivent le mouvement sans qu’il soit nécessaire de modifier leurs transformations locales. C’est exactement le comportement attendu : tourner le torse d’un personnage entraîne naturellement tout le haut du corps.
Un objet articulé est un cas particulier de hiérarchie de repères dans lequel les nœuds sont des articulations (joints) reliées par des segments rigides. Le squelette d’un personnage en est l’exemple le plus courant : chaque articulation (épaule, coude, poignet, hanche, genou, cheville…) définit un repère local, et la transformation locale de chaque articulation est typiquement une rotation (les os ne se déforment pas, ils pivotent autour des articulations).
Considérons l’exemple d’un bras articulé simplifié à deux segments (bras + avant-bras) dans le plan :
La transformation globale du coude est :
\[ M_{\text{coude}} = T(\mathbf{p}_0) \; R(\alpha) \; T(L_1, 0, 0) \]
La transformation globale de la main est :
\[ M_{\text{main}} = \underbrace{T(\mathbf{p}_0) \; R(\alpha) \; T(L_1, 0, 0)}_{M_{\text{coude}}} \; R(\beta) \; T(L_2, 0, 0) \]
On retrouve le motif répétitif : à chaque articulation, on compose une rotation locale (l’angle de l’articulation) suivie d’une translation le long du segment (la longueur de l’os). Pour animer le bras, il suffit de faire varier les angles \(\alpha(t)\) et \(\beta(t)\) au cours du temps — les positions globales de tous les points se mettent à jour automatiquement par propagation dans la chaîne.
Ce modèle se généralise directement en 3D : chaque articulation possède une rotation 3D (typiquement stockée sous forme de quaternion pour l’interpolation), et la transformation locale inclut la translation le long de l’os.
À l’échelle d’une scène complète, la hiérarchie de repères se généralise en un graphe de scène (scene graph). C’est une structure arborescente (ou plus généralement un DAG — graphe acyclique orienté) dans laquelle chaque nœud porte une transformation locale et peut contenir de la géométrie, des sources de lumière, des caméras, ou d’autres nœuds enfants.
Un graphe de scène typique pourrait avoir la structure suivante :
Scène (racine)
├── Terrain
├── Personnage
│ ├── Torse
│ │ ├── Bras_gauche
│ │ │ ├── Avant_bras_gauche
│ │ │ │ └── Main_gauche
│ │ │ ...
│ │ └── Tête
│ └── Jambe_gauche
│ └── Pied_gauche
├── Véhicule
│ ├── Châssis
│ ├── Roue_avant_gauche
│ ├── Roue_avant_droite
│ ...
└── CaméraLa mise à jour des coordonnées globales consiste à parcourir les nœuds dans l’ordre de la hiérarchie (les parents avant les enfants) et à composer chaque transformation locale avec la transformation globale du parent.
En pratique, une implémentation efficace représente chaque nœud par sa géométrie, un identifiant, l’identifiant de son parent, et sa transformation locale :
struct node {
mesh geometry; // géométrie associée au nœud
std::string name; // identifiant du nœud
std::string name_parent; // identifiant du parent
mat4 transform_local; // transformation par rapport au parent
mat4 transform_global; // transformation dans le repère monde
};Les nœuds sont stockés dans un tableau ordonné de sorte que chaque parent apparaisse avant ses enfants, et une table de correspondance nom \(\to\) index permet de retrouver rapidement un nœud :
struct hierarchy {
std::vector<node> elements; // parents avant enfants
std::map<std::string, int> index; // accès rapide par nom
};La propagation des transformations se réduit alors à un simple parcours linéaire du tableau :
int const N = elements.size();
for (int k = 0; k < N; ++k) {
auto& element = elements[k];
if (element est un nœud racine) {
// La transformation globale est la transformation locale
element.transform_global = element.transform_local;
}
else {
// Composition avec la transformation globale du parent
auto const& local = element.transform_local;
auto const& global_parent
= elements[index_parent].transform_global;
element.transform_global = global_parent * local;
}
}L’algorithme est en \(O(N)\) : chaque nœud est visité une seule fois, et la transformation globale du parent est déjà calculée grâce à l’ordre du tableau. Pour animer la hiérarchie, il suffit de modifier les transformations locales des nœuds souhaités, puis de relancer cette propagation avant le rendu.
Avantages du graphe de scène :
La matrice View transforme les coordonnées du world space (repère global de la scène) en coordonnées du view space (repère attaché à la caméra, dans lequel la caméra est à l’origine et regarde dans la direction \(-z\)). Cette transformation est nécessaire car le pipeline de rendu travaille dans l’espace caméra pour la projection perspective (voir le chapitre sur le pipeline de rendu).
La caméra est définie dans le world space par sa position \(\mathbf{eye}\) et son repère local constitué de trois vecteurs orthonormés : \(\mathbf{right}\) (direction droite), \(\mathbf{up}\) (direction haut) et \(\mathbf{back}\) (direction opposée à la direction de visée). La matrice caméra \(\text{Cam}\) est la matrice \(4 \times 4\) qui transforme les coordonnées du view space en coordonnées du world space — c’est la matrice dont les colonnes sont les vecteurs du repère caméra exprimés dans le repère monde :
\[ \text{Cam} = \begin{pmatrix} | & | & | & | \\ \mathbf{right} & \mathbf{up} & \mathbf{back} & \mathbf{eye} \\ | & | & | & | \\ 0 & 0 & 0 & 1 \end{pmatrix} = \begin{pmatrix} O & \mathbf{eye} \\ 0 & 1 \end{pmatrix} \]
où \(O = (\mathbf{right} \;|\; \mathbf{up} \;|\; \mathbf{back})\) est la matrice \(3 \times 3\) d’orientation. La matrice de vue est son inverse (elle effectue la transformation dans l’autre sens : world \(\to\) view) :
\[ \text{View} = \text{Cam}^{-1} = \begin{pmatrix} O^T & -O^T \, \mathbf{eye} \\ 0 & 1 \end{pmatrix} \]
L’inverse se calcule simplement car \(\text{Cam}\) est une transformation rigide (rotation + translation) : la rotation s’inverse par transposition (\(O^{-1} = O^T\)) et la translation s’inverse en \(-O^T \mathbf{eye}\). On peut vérifier que \(\text{View} \times \mathbf{eye} = (0, 0, 0, 1)\) : la position de la caméra est bien à l’origine dans le view space.
En pratique, la matrice de vue est souvent construite via une
fonction lookAt(eye, center, up_hint) qui calcule le repère
caméra à partir de la position de la caméra (\(\mathbf{eye}\)), du point visé (\(\mathbf{center}\)) et d’un vecteur “haut”
approximatif (\(\mathbf{up\_hint}\),
typiquement l’axe \(y\)). L’algorithme
est :
Une approche simple pour contrôler la caméra dans un visualiseur 3D consiste à paramétrer sa position en coordonnées sphériques \((\theta, \varphi, r)\) autour d’un point central \(\mathbf{center}\). La caméra orbite sur une sphère de rayon \(r\), et l’utilisateur contrôle la latitude \(\varphi\) et la longitude \(\theta\) avec la souris, le rayon \(r\) avec la molette.
La position de la caméra est alors :
\[ \mathbf{eye} = \mathbf{center} + r \, (\cos\varphi \cos\theta, \; \sin\varphi, \; \cos\varphi \sin\theta) \]
et la matrice de vue se reconstruit à chaque frame via
lookAt(eye, center, up).
Avantages : implémentation simple, pratique pour orbiter autour d’une structure avec une orientation naturelle (bâtiment, personnage debout).
Inconvénients : il manque un degré de liberté —
l’orientation de la caméra est entièrement déterminée par sa position
sur la sphère, sans possibilité de rotation de twist
(roulis autour de l’axe de visée). De plus, aux pôles (\(\varphi = \pm \pi/2\)), le vecteur \(\mathbf{up\_hint}\) devient parallèle à la
direction de visée, ce qui provoque une dégénérescence (le produit
vectoriel dans lookAt donne un vecteur nul). Enfin, si
l’objet observé a une orientation initiale qui ne correspond pas à la
convention “haut = \(y\)”, les
mouvements de souris ne correspondent plus aux rotations attendues.
L’approche ArcBall (ou Trackball), proposée par K. Shoemake (ARCBALL: A User Interface for Specifying Three-Dimensional Orientation Using a Mouse, Graphics Interface, 1992), offre 3 degrés de liberté pour l’orientation de la caméra et résout les limitations des coordonnées sphériques.
L’idée est la suivante : on imagine une sphère virtuelle (le trackball) centrée au milieu de l’écran. Lorsque l’utilisateur clique et fait glisser la souris, les deux positions du curseur (début et fin du drag) sont projetées sur cette sphère, produisant deux points 3D. La rotation qui amène le premier point sur le second définit la rotation à appliquer à la caméra (ou à l’objet).
L’algorithme est le suivant. Soient \(\mathbf{p}_1 = (p_{1x}, p_{1y})\) et \(\mathbf{p}_2 = (p_{2x}, p_{2y})\) deux positions du curseur en coordonnées écran normalisées (dans \([-1, 1]\)) :
La projection sur le trackball utilise une sphère pour les positions proches du centre et une extension hyperbolique pour les positions éloignées (afin de couvrir tout l’écran) :
\[ \text{ProjectionArcBall}(\mathbf{p}) = \begin{cases} (\mathbf{p}, \sqrt{1 - d^2}) & \text{si } d < 1/\sqrt{2} \quad \text{(sphère)} \\ (\mathbf{p}, 1/(2d)) & \text{sinon} \quad \text{(hyperbole)} \end{cases} \]
avec \(d = \|\mathbf{p}\|\). Le raccord entre la sphère et l’hyperbole se fait à \(d = 1/\sqrt{2}\), point auquel les deux fonctions (\(\sqrt{1-d^2}\) et \(1/(2d)\)) coïncident en valeur et en dérivée, assurant une transition lisse.
Avantages : rotation naturelle autour des formes, pas d’axe privilégié (contrairement aux coordonnées sphériques qui singularisent les pôles), comportement invariant quelle que soit l’orientation initiale de l’objet.
Inconvénients : la rotation obtenue est moins “propre” qu’un contrôle individuel de chaque axe (pitch, yaw, roll) — ce qui peut gêner pour des mouvements de caméra très précis. De plus, des mouvements de va-et-vient rapides de la souris provoquent un léger drift (dérive de l’orientation), car la discrétisation des positions du curseur introduit de petites erreurs cumulatives.
L’approche traditionnelle de l’animation consiste à définir manuellement la trajectoire des objets — soit par des images-clés (l’animateur fixe la position et l’orientation à certains instants, puis le logiciel interpole entre ces poses), soit par des mouvements procéduraux scriptés (par exemple, faire tourner une roue à vitesse constante). Cette approche fonctionne très bien tant que le mouvement reste prévisible et que l’animateur peut en concevoir mentalement la forme.
Mais de nombreux phénomènes échappent à ce contrôle direct. Une cape qui se froisse au gré du vent, un fluide qui s’écoule, un tas de billes qui s’effondre, une chevelure qui suit le mouvement d’un personnage : dans tous ces cas, la dynamique elle-même est l’effet recherché. La forme finale n’est pas connue à l’avance ; elle émerge des interactions entre de nombreux éléments soumis à des forces. Tenter de spécifier manuellement la position de chaque pli ou de chaque goutte serait à la fois fastidieux et peu convaincant.



Trois exemples de phénomènes nécessitant une simulation physique : fluides, tissu, dynamique d'objets rigides multiples.
C’est dans ces situations que la simulation physique devient indispensable : on confie au calcul la tâche de générer le mouvement, en partant d’une description du système et de lois d’évolution. Le résultat est obtenu non pas en dessinant la trajectoire, mais en la déduisant d’un modèle mathématique.
Toute simulation physique, quel que soit le phénomène modélisé, suit la même démarche en trois étapes.
Description du système. On choisit d’abord les paramètres qui caractérisent l’état du système à un instant donné : positions, vitesses, orientations, températures, densités, etc. L’état est typiquement connu à l’instant initial \(t = 0\) — c’est un problème de valeur initiale dans le temps. Il peut également être contraint dans l’espace (par exemple, le tissu accroché à un point fixe) — c’est un problème de valeur aux bords dans l’espace.
Évolution du système. On relie ensuite cette évolution à des forces ou à des contraintes via les principes de la dynamique (typiquement la deuxième loi de Newton) ou des lois de conservation. Cette étape produit une équation différentielle qui exprime comment l’état évolue dans le temps.
Résolution numérique. Sauf cas exceptionnels (ressort linéaire isolé, chute libre, etc.), l’équation différentielle ne possède pas de solution analytique simple. On la résout alors numériquement, en discrétisant le temps et en construisant la trajectoire pas à pas, à partir de l’état initial.
Cette approche est fondamentalement différente de l’animation par images-clés. Avec une simulation, on ne décrit que l’état initial et les lois d’évolution ; la trajectoire complète est ensuite calculée par le solveur. Cela offre un grand pouvoir descriptif (il devient possible de modéliser des comportements complexes avec peu de paramètres) au prix d’une perte de contrôle direct : on ne peut pas garantir précisément où se trouvera tel objet à tel instant, et il faut souvent expérimenter avec les paramètres pour obtenir l’effet visuel souhaité.
Le système le plus simple à simuler est la particule : un point matériel décrit entièrement par sa position \(\mathbf{p}(t) \in \mathbb{R}^3\), sa vitesse \(\mathbf{v}(t) \in \mathbb{R}^3\) et sa masse \(m \in \mathbb{R}^+\). Les autres grandeurs dynamiques se déduisent de ces paramètres : la quantité de mouvement linéaire \(\mathbf{P} = m \, \mathbf{v}\), l’énergie cinétique \(E_c = \frac{1}{2} m \, \|\mathbf{v}\|^2\), etc.

La quantité de mouvement joue un rôle privilégié : elle est conservée dans tout système isolé (sans force extérieure). Cette propriété est exploitée plus loin pour modéliser les collisions entre sphères.
L’évolution de la particule est décrite par le principe fondamental de la dynamique : si une force \(\mathbf{F}(\mathbf{p}, \mathbf{v}, t)\) agit sur la particule, alors
\[ \left\{ \begin{array}{l} \mathbf{p}'(t) = \mathbf{v}(t) \\[0.5em] m \, \mathbf{v}'(t) = \mathbf{F}(\mathbf{p}, \mathbf{v}, t) \end{array} \right. \]
La première équation est la définition de la vitesse comme dérivée temporelle de la position ; la seconde est la loi de Newton. Ce système constitue une équation différentielle ordinaire (EDO) du premier ordre lorsqu’on regroupe \((\mathbf{p}, \mathbf{v})\) en un seul vecteur d’état. La force peut dépendre de la position (gravité dépendante de l’altitude, ressort), de la vitesse (frottement visqueux), ou du temps (vent variable).
D’autres formalismes sont possibles pour décrire la même dynamique — la conservation de l’énergie (\(E_c + E_p = \mathrm{cste}\) pour un système conservatif), la mécanique lagrangienne ou hamiltonienne en coordonnées généralisées. Pour les besoins de l’informatique graphique, la formulation newtonienne en coordonnées cartésiennes est la plus directe et reste la plus utilisée.
Cette section couvre la dynamique physique des particules : forces, équations du mouvement, intégration numérique. Les aspects spécifiques au rendu d’un système de particules (billboards, durée de vie, recyclage, attributs visuels) ont été abordés au chapitre précédent (voir « Particules et bruit procédural »).
Sauf cas pathologiques (force constante, ressort linéaire isolé), l’EDO ne se résout pas par intégration symbolique. La stratégie générale consiste à discrétiser le temps. On choisit un pas de temps \(h = \Delta t\) et on construit une suite d’états aux instants \(t^k = k \, h\) :
\[ \mathbf{p}^k \simeq \mathbf{p}(t^k), \quad \mathbf{v}^k \simeq \mathbf{v}(t^k) \]
Le schéma le plus simple, dit schéma d’Euler explicite, consiste à approximer chaque dérivée par une différence finie avant :
\[ \left\{ \begin{array}{l} \mathbf{v}^{k+1} = \mathbf{v}^k + h \, \mathbf{F}(\mathbf{p}^k, \mathbf{v}^k, t^k) / m \\[0.5em] \mathbf{p}^{k+1} = \mathbf{p}^k + h \, \mathbf{v}^{k+1} \end{array} \right. \]
Ce schéma est trivial à implémenter : à chaque pas de temps, on évalue la force à l’état courant, on met à jour la vitesse, puis on met à jour la position avec la nouvelle vitesse. Pour des problèmes simples (gravité constante, par exemple), il fournit des résultats raisonnables. Mais comme on le verra plus loin (analyse du ressort 1D), il devient instable dès que la force varie rapidement avec la position : l’énergie du système croît artificiellement à chaque pas, et la simulation diverge. Cette limitation motivera l’introduction d’une variante semi-implicite plus stable.
Le premier exemple non trivial consiste à simuler un ensemble de sphères rigides soumises à la gravité, susceptibles d’entrer en collision avec des obstacles fixes (sols, murs) et entre elles. C’est le modèle classique d’un tas de billes qui tombent, d’une boule de billard qui rebondit, ou d’un nuage de particules grossières qui s’agglutinent.

L’idée centrale est de réduire chaque sphère à une particule située en son centre, augmentée d’un rayon \(r_i\). Le système est donc décrit par \(N\) particules de paramètres \((\mathbf{p}_i, \mathbf{v}_i, m_i, r_i)\), \(i \in \{0, \ldots, N-1\}\), avec conditions initiales \(\mathbf{p}_i(0) = \mathbf{p}_i^0\) et \(\mathbf{v}_i(0) = \mathbf{v}_i^0\).
Les forces appliquées sont la gravité \(\mathbf{F}_i = m_i \, \mathbf{g}\) (avec typiquement \(\mathbf{g} = (0, -9.81, 0)\) m/s²). Les collisions, qui sont par nature instantanées, ne sont pas modélisées comme des forces continues mais comme des impulsions — des changements brutaux de vitesse appliqués à l’instant du contact. Entre deux collisions, l’évolution est libre :
\[ \mathbf{p}_i'(t) = \mathbf{v}_i(t), \quad \mathbf{v}_i'(t) = \mathbf{g} \]
La discrétisation par Euler explicite donne, pour chaque particule :
\[ \left\{ \begin{array}{l} \mathbf{v}_i^{k+1} = \mathbf{v}_i^k + h \, \mathbf{g} \\[0.5em] \mathbf{p}_i^{k+1} = \mathbf{p}_i^k + h \, \mathbf{v}_i^{k+1} \end{array} \right. \]
À chaque pas de temps, on intègre d’abord librement chaque sphère, puis on applique deux étapes correctives : détection des collisions et réponse à ces collisions. Ces deux étapes font tout le sel de la simulation et sont détaillées dans les sections suivantes.
Considérons un plan \(\mathcal{P}\) (par exemple le sol), paramétré par un point \(\mathbf{a}\) qui lui appartient et par une normale unitaire \(\mathbf{n}\) pointant vers la zone autorisée (typiquement vers le haut pour un sol). Tout point \(\mathbf{p}\) du plan vérifie l’équation cartésienne :
\[ (\mathbf{p} - \mathbf{a}) \cdot \mathbf{n} = 0 \]
Pour une sphère de centre \(\mathbf{p}_i\) et rayon \(r_i\), on peut classer sa position par rapport au plan :

L’algorithme de détection est immédiat : on parcourt toutes les sphères et on teste cette condition. Lorsqu’elle est vraie, on déclenche la réponse à la collision.
for (int i = 0; i < N; ++i) {
float detection = dot(p[i] - a, n);
if (detection <= r[i]) {
// ... réponse à la collision (vitesse + position)
}
}Ce test coûte \(O(N)\) par plan. Pour un environnement comportant plusieurs plans (sol + murs), on multiplie le coût par le nombre de plans. Pour des géométries plus complexes (mesh quelconque), on emploie des structures spatiales (BVH, grille uniforme, octree) afin d’éliminer rapidement les sphères trop éloignées.
Supposons d’abord que la collision est détectée à l’instant exact du contact, c’est-à-dire \((\mathbf{p}_i - \mathbf{a}) \cdot \mathbf{n} = r_i\). Il faut alors choisir la nouvelle vitesse \(\mathbf{v}^{\text{new}}\) après collision.
L’idée géométrique est de décomposer la vitesse en deux composantes par rapport à la normale au plan :
\[ \mathbf{v} = \mathbf{v}_\perp + \mathbf{v}_\parallel \qquad \text{avec} \qquad \mathbf{v}_\perp = (\mathbf{v} \cdot \mathbf{n}) \, \mathbf{n}, \quad \mathbf{v}_\parallel = \mathbf{v} - (\mathbf{v} \cdot \mathbf{n}) \, \mathbf{n} \]
La composante perpendiculaire \(\mathbf{v}_\perp\) est responsable de l’impact (la sphère vient frapper le plan), tandis que la composante parallèle \(\mathbf{v}_\parallel\) représente le glissement sur le plan.

La nouvelle vitesse s’obtient en pondérant ces deux composantes par des coefficients de restitution :
\[ \mathbf{v}^{\text{new}} = \alpha \, \mathbf{v}_\parallel - \beta \, \mathbf{v}_\perp \]
avec \(\alpha, \beta \in [0, 1]\). Le signe « − » devant \(\mathbf{v}_\perp\) inverse la composante normale : la sphère qui descendait remonte. Les coefficients ont une interprétation physique claire :
Ce modèle est extrêmement simplifié — il ignore les effets de rotation, le frottement de Coulomb anisotrope, etc. — mais il suffit largement pour la plupart des effets visuels.
En pratique, comme les collisions ne sont détectées qu’à des instants discrets \(t^k\), le contact n’est jamais exact : entre deux pas de temps, la sphère peut s’enfoncer dans le plan, et au moment où la collision est détectée on a typiquement \((\mathbf{p}_i - \mathbf{a}) \cdot \mathbf{n} < r_i\). Il faut donc, en plus de la mise à jour de la vitesse, corriger la position pour rétablir une configuration physiquement plausible.



Trois stratégies pour gérer la pénétration : (1) ajuster la vitesse pour ressortir, (2) reprojeter la position sur la surface, (3) revenir à l'instant exact du contact.
Trois grandes stratégies coexistent.
(1) Mettre à jour la vitesse pour faire ressortir la sphère. On ne corrige pas explicitement la position, mais on choisit la nouvelle vitesse de sorte que, au prochain pas de temps, la sphère se retrouve hors du plan. C’est l’approche la plus simple lorsque le volume de pénétration est faible. Elle est très légère à implémenter et ne produit pas de discontinuité visible, mais la sphère reste « en collision » pendant un ou plusieurs pas de temps, ce qui peut donner des artefacts (vibration, attache au plan).
(2) Corriger la position en projetant sur la surface de contact. On déplace immédiatement le centre de la sphère pour annuler la pénétration : \(\mathbf{p}_i \leftarrow \mathbf{p}_i + d \, \mathbf{n}\), avec \(d = r_i - (\mathbf{p}_i - \mathbf{a}) \cdot \mathbf{n}\). C’est le principe de la dynamique basée sur la position (Position-Based Dynamics, PBD), très répandu dans les jeux vidéo. L’approche est simple, robuste et élimine la pénétration en un seul pas — au prix d’une exactitude physique réduite, puisque la sphère « téléporte » et que l’énergie cinétique n’est plus exactement conservée.
(3) Revenir en arrière dans le temps pour trouver l’instant exact du contact. On résout l’équation \((\mathbf{p}_i(t^*) - \mathbf{a}) \cdot \mathbf{n} = r_i\) pour \(t^* \in [t^k, t^{k+1}]\), on applique la réponse en vitesse à cet instant, puis on intègre librement de \(t^*\) jusqu’à \(t^{k+1}\). C’est la détection continue de collisions (Continuous Collision Detection, CCD). Elle est physiquement précise et gère correctement les collisions très rapides (tunnelling), mais coûte plus cher : il faut typiquement une recherche binaire (ou la résolution d’une équation polynomiale) pour chaque collision, et gérer les cas où plusieurs collisions ont lieu pendant le même pas de temps.
En pratique, les implémentations grand public (jeux vidéo, animations en temps réel) combinent souvent (1) et (2) — réponse en vitesse + petite reprojection — qui offre un bon compromis entre coût et qualité. Le CCD est réservé aux situations où l’exactitude est critique (simulation scientifique, vêtements rapides à fort risque de tunnelling).
On considère maintenant deux sphères en mouvement, de paramètres \((\mathbf{p}_1, \mathbf{v}_1, m_1, r_1)\) et \((\mathbf{p}_2, \mathbf{v}_2, m_2, r_2)\). La condition de collision est purement géométrique : les deux sphères se touchent dès que la distance entre leurs centres devient inférieure à la somme de leurs rayons.
\[ \|\mathbf{p}_1 - \mathbf{p}_2\| \le r_1 + r_2 \]

La détection est triviale ; la question intéressante est : que deviennent les vitesses après la collision ? Autrement dit, comment calculer \(\mathbf{v}_1^{\text{new}}\) et \(\mathbf{v}_2^{\text{new}}\) à partir de \(\mathbf{v}_1\) et \(\mathbf{v}_2\) ? C’est ici que la conservation de la quantité de mouvement et de l’énergie cinétique entre en jeu.
Lors d’une collision, les deux sphères s’échangent de la quantité de mouvement par l’intermédiaire d’impulsions \(\mathbf{J}_1\) et \(\mathbf{J}_2\) — des forces de très grande intensité agissant pendant un temps très court. L’expérience montre (et la mécanique classique confirme) que ces impulsions sont dirigées le long de la droite des centres : il n’y a pas de force tangentielle dans une collision idéale entre sphères lisses.
On définit donc le vecteur unitaire de séparation :
\[ \mathbf{u} = \frac{\mathbf{p}_1 - \mathbf{p}_2}{\|\mathbf{p}_1 - \mathbf{p}_2\|} \]
et on cherche les impulsions sous la forme \(\mathbf{J}_1 = j \, \mathbf{u}\), \(\mathbf{J}_2 = -j \, \mathbf{u}\) avec \(j\) scalaire à déterminer. Le signe opposé entre les deux impulsions découle directement de la conservation de la quantité de mouvement linéaire du système isolé formé par les deux sphères :
\[ m_1 \mathbf{v}_1 + m_2 \mathbf{v}_2 = m_1 \mathbf{v}_1^{\text{new}} + m_2 \mathbf{v}_2^{\text{new}} \]
En réarrangeant :
\[ m_1 (\mathbf{v}_1^{\text{new}} - \mathbf{v}_1) = - m_2 (\mathbf{v}_2^{\text{new}} - \mathbf{v}_2) \quad \Longleftrightarrow \quad \mathbf{J}_1 = -\mathbf{J}_2 \]
ce qui est précisément la troisième loi de Newton appliquée à l’interaction de contact : action et réaction sont égales et opposées.
Les vitesses après collision s’écrivent alors :
\[ \mathbf{v}_1^{\text{new}} = \mathbf{v}_1 + \frac{j}{m_1} \mathbf{u}, \quad \mathbf{v}_2^{\text{new}} = \mathbf{v}_2 - \frac{j}{m_2} \mathbf{u} \]
Il reste à déterminer le scalaire \(j\), qui dépend du modèle physique de collision choisi.
Le modèle le plus courant suppose une collision élastique (collision de « sphères dures ») : aucune énergie n’est dissipée, l’énergie cinétique du système est intégralement conservée.
\[ \frac{1}{2} m_1 \|\mathbf{v}_1\|^2 + \frac{1}{2} m_2 \|\mathbf{v}_2\|^2 = \frac{1}{2} m_1 \|\mathbf{v}_1^{\text{new}}\|^2 + \frac{1}{2} m_2 \|\mathbf{v}_2^{\text{new}}\|^2 \]
En substituant les expressions de \(\mathbf{v}_1^{\text{new}}\) et \(\mathbf{v}_2^{\text{new}}\) et en développant les normes au carré :
\[ m_1 \|\mathbf{v}_1\|^2 + m_2 \|\mathbf{v}_2\|^2 = m_1 \left\| \mathbf{v}_1 + \frac{j}{m_1} \mathbf{u} \right\|^2 + m_2 \left\| \mathbf{v}_2 - \frac{j}{m_2} \mathbf{u} \right\|^2 \]
En utilisant \(\|\mathbf{a} + \mathbf{b}\|^2 = \|\mathbf{a}\|^2 + 2\mathbf{a}\cdot\mathbf{b} + \|\mathbf{b}\|^2\) et le fait que \(\|\mathbf{u}\| = 1\), les termes \(m_i \|\mathbf{v}_i\|^2\) se simplifient des deux côtés et il reste :
\[ 0 = 2 j \, \mathbf{v}_1 \cdot \mathbf{u} + \frac{j^2}{m_1} - 2 j \, \mathbf{v}_2 \cdot \mathbf{u} + \frac{j^2}{m_2} \]
En factorisant par \(j\) (la solution \(j = 0\) correspond au cas trivial sans interaction) :
\[ j = \frac{2}{1/m_1 + 1/m_2} \, (\mathbf{v}_2 - \mathbf{v}_1) \cdot \mathbf{u} = 2 \, \frac{m_1 \, m_2}{m_1 + m_2} \, (\mathbf{v}_2 - \mathbf{v}_1) \cdot \mathbf{u} \]
La quantité \(\mu = m_1 m_2 / (m_1 + m_2)\) est la masse réduite du système, qui apparaît naturellement dans tous les problèmes à deux corps. La quantité \((\mathbf{v}_2 - \mathbf{v}_1) \cdot \mathbf{u}\) est la vitesse relative d’approche des deux sphères : elle est positive lorsque les sphères se rapprochent, ce qui donne \(j > 0\) et inverse correctement les vitesses normales.
Pour modéliser des collisions partiellement inélastiques (perte d’énergie), on multiplie l’impulsion par un facteur \(\alpha \in [0, 1]\) identique au coefficient de restitution \(\beta\) utilisé pour la collision avec un plan.
Comme pour la collision avec un plan, deux approches dominent en pratique. Elles partagent la même étape de détection mais diffèrent par la manière de combiner correction de vitesse et correction de position.
L’approche basée sur la position (PBD) procède en trois étapes à chaque pas de temps.
L’approche basée sur la vitesse utilise la même détection, mais n’effectue la mise à jour de la vitesse que si les deux sphères sont effectivement en train de se rapprocher, c’est-à-dire si \((\mathbf{v}_1 - \mathbf{v}_2) \cdot \mathbf{n} < 0\) (avec \(\mathbf{n} = \mathbf{u}\)). Cette condition empêche d’appliquer une seconde impulsion à des sphères qui ont déjà rebondi mais qui restent encore légèrement en pénétration au pas de temps suivant — un piège classique qui produit des « collements » et des vibrations indésirables.
Le choix entre les deux approches dépend du contexte. PBD est privilégiée pour la robustesse et la simplicité (notamment dans les moteurs de jeu). La variante basée sur la vitesse est plus proche de la physique mais demande un peu plus de soin dans l’implémentation.
Tester naïvement toutes les paires de sphères coûte \(O(N^2)\) et devient prohibitif dès quelques milliers de particules : en pratique on intercale une étape de broad-phase (typiquement une grille uniforme indexée par la position, ou un BVH) qui élimine en \(O(N)\) les paires manifestement trop éloignées, avant de ne traiter en détail que les paires candidates.
Les éléments précédents s’assemblent en une boucle simple, exécutée à chaque pas de temps \(h\) :
// Pour chaque pas de temps t -> t + h
for (int i = 0; i < N; ++i) {
// 1. Intégration libre (Euler explicite ici, semi-implicite plus loin)
v[i] += h * g;
p[i] += h * v[i];
}
// 2. Détection + réponse aux collisions avec les obstacles
for (int i = 0; i < N; ++i) {
for (Plane const& P : planes)
if (dot(p[i] - P.a, P.n) <= r[i])
respond_plane(p[i], v[i], r[i], P);
}
// 3. Détection + réponse aux collisions sphère-sphère
for (auto [i, j] : broadphase.candidate_pairs()) {
if (length(p[i] - p[j]) <= r[i] + r[j])
respond_sphere(p[i], v[i], m[i], r[i],
p[j], v[j], m[j], r[j]);
}L’ordre des étapes a son importance : on intègre d’abord librement (la trajectoire prédite peut violer les contraintes), puis on corrige par les réponses de collision. Lorsque plusieurs collisions se produisent au même pas de temps, on les traite typiquement en plusieurs itérations successives jusqu’à stabilisation — ce qui peut introduire un coût supplémentaire si le système est très contraint (par exemple un tas de billes au repos).
Avant d’attaquer la simulation de tissu (qui combine de nombreux ressorts en interaction), commençons par le cas le plus élémentaire : une particule attachée à un ressort en une dimension. Ce système, l’oscillateur harmonique, joue un rôle paradigmatique en physique car il admet une solution analytique exacte qui sert de référence pour évaluer les schémas numériques.

La force exercée par le ressort sur la particule de position \(p(t)\) s’écrit, selon la loi de Hooke :
\[ F(t) = -k \, (p(t) - l^0) \]
où \(k > 0\) est la rigidité du ressort et \(l^0\) sa longueur de repos. Le signe « − » exprime que la force ramène toujours la particule vers sa position d’équilibre \(p = l^0\) : si le ressort est étiré (\(p > l^0\)), la force est dirigée vers le centre ; s’il est comprimé (\(p < l^0\)), elle pousse vers l’extérieur.
L’équation du mouvement est une EDO linéaire du second ordre :
\[ m \, p''(t) + k \, p(t) = k \, l^0 \]
En posant \(u = (p, v)^T\), on la reformule en système du premier ordre :
\[ \underbrace{\begin{pmatrix} p \\ v \end{pmatrix}'(t)}_{u'(t)} = \underbrace{\begin{pmatrix} v(t) \\ -\frac{k}{m} (p(t) - l^0) \end{pmatrix}}_{\mathcal{F}(u, t)} \]
et même, en isolant la partie linéaire :
\[ u'(t) = \mathrm{A} \, u(t) + \mathbf{b}, \quad \mathrm{A} = \begin{pmatrix} 0 & 1 \\ -k/m & 0 \end{pmatrix}, \quad \mathbf{b} = \begin{pmatrix} 0 \\ k\,l^0/m \end{pmatrix} \]
Le système étant linéaire, on connaît la solution exacte :
\[ p(t) = A \, \sin(\omega \, t + \varphi) + l^0 \]
avec \(\omega = \sqrt{k/m}\) la pulsation propre, et l’amplitude \(A\) et la phase \(\varphi\) déterminées par les conditions initiales :
\[ A^2 = (p^0 - l^0)^2 + \left(\frac{v^0}{\omega}\right)^2, \quad \tan \varphi = \frac{p^0 - l^0}{v^0 / \omega} \]
La trajectoire est donc une oscillation sinusoïdale parfaite et indéfinie autour de la position d’équilibre. L’énergie totale (cinétique + potentielle élastique) reste constante.
C’est précisément cette propriété — la conservation exacte de l’énergie — qui rend le ressort 1D si utile pour analyser les schémas numériques : tout schéma dont la simulation s’éloigne de l’oscillation parfaite révèle un défaut systématique (gain ou perte d’énergie artificielle).
Le passage en trois dimensions complique nettement le problème. Considérons une particule attachée à un ressort dont l’autre extrémité est fixée à l’origine, soumise à la gravité. La force totale est la somme de la gravité et de la force élastique radiale :
\[ \mathbf{F}(t) = m \, \mathbf{g} - k \, (\|\mathbf{p}(t)\| - l^0) \, \frac{\mathbf{p}(t)}{\|\mathbf{p}(t)\|} \]
Le terme \(\mathbf{p}/\|\mathbf{p}\|\) est le vecteur unitaire orienté du point d’attache vers la particule, et l’intensité du rappel est proportionnelle à l’allongement \(\|\mathbf{p}\| - l^0\).

L’équation différentielle du second ordre s’écrit :
\[ m \, \mathbf{p}''(t) = m \, \mathbf{g} - k \, (\|\mathbf{p}(t)\| - l^0) \, \frac{\mathbf{p}(t)}{\|\mathbf{p}(t)\|} \]
Ou, en système du premier ordre :
\[ \begin{pmatrix} \mathbf{p} \\ \mathbf{v} \end{pmatrix}'(t) = \begin{pmatrix} \mathbf{v}(t) \\ \mathbf{g} - \frac{k}{m} (\|\mathbf{p}(t)\| - l^0) \, \frac{\mathbf{p}(t)}{\|\mathbf{p}(t)\|} \end{pmatrix} \]
Contrairement au cas 1D, ce système est non linéaire à cause de la dépendance en \(\|\mathbf{p}\|\). Il n’admet plus de solution analytique simple (la trajectoire est une combinaison complexe d’oscillations radiales et tangentielles, parfois apériodique). On doit donc recourir à l’intégration numérique, ce qui rend d’autant plus crucial le choix d’un schéma stable.
Pour simuler un tissu, l’idée naturelle est de l’échantillonner par une grille régulière de \(N \times N\) particules, chacune de masse \(m\). La masse totale du tissu vaut donc \(N^2 m\). Reste à connecter ces particules par un réseau de ressorts qui reproduise le comportement mécanique souhaité.
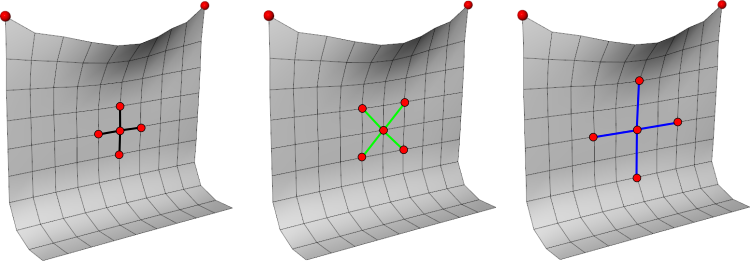
Trois familles de ressorts sont classiquement utilisées, chacune ciblant un mode de déformation particulier :
Si l’on n’utilise que les ressorts structurels, le réseau ne contraint que les longueurs d’arêtes. Or, deux configurations très différentes peuvent partager les mêmes longueurs d’arêtes : un carré et un losange aplati, par exemple. Le tissu peut alors se cisailler ou se plier à coût nul, ce qui produit des artefacts visuels disgracieux (formation de plis aigus, perte de volume).

Avec des ressorts structurels seulement, le tissu peut se cisailler ou se plier librement à coût énergétique nul.
L’ajout des ressorts de cisaillement (diagonales) résout le premier problème : tout cisaillement modifie la longueur des diagonales et est donc pénalisé. L’ajout des ressorts de flexion (voisins à 2 anneaux) résout le second : tout pliage entre trois particules colinéaires modifie la distance entre les particules extrêmes et coûte donc de l’énergie.

Ajout des ressorts de cisaillement (diagonales courtes) et de flexion (voisinage à 2 anneaux) pour rigidifier le tissu.
Les rigidités \(K_{ij}\) associées à chaque famille sont en général différentes : \(K_{\text{struct}} > K_{\text{shear}} > K_{\text{bend}}\), reflétant le fait que l’allongement est typiquement le mode de déformation le plus coûteux énergétiquement.
Chaque particule \(i\) du tissu subit trois types de forces : la gravité, une force de traînée (modélisant la résistance de l’air, qui amortit les oscillations parasites) et la somme des forces élastiques exercées par tous les ressorts auxquels elle est connectée. La force totale s’écrit :
\[ \mathbf{F}_i(\mathbf{p}, \mathbf{v}, t) = m_i \, \mathbf{g} - \mu \, \mathbf{v}_i(t) + \sum_{j \in \mathcal{V}_i} K_{ij} \, \big( \|\mathbf{p}_j(t) - \mathbf{p}_i(t)\| - L_{ij}^0 \big) \, \frac{\mathbf{p}_j(t) - \mathbf{p}_i(t)}{\|\mathbf{p}_j(t) - \mathbf{p}_i(t)\|} \]
où :
Le terme élastique correspond exactement à la loi de Hooke généralisée : son intensité est proportionnelle à l’écart à la longueur de repos, et sa direction est celle du ressort. Le terme de traînée \(-\mu \mathbf{v}_i\) est essentiel en pratique : sans amortissement, le système oscillerait éternellement (les ressorts conservent l’énergie élastique).
L’EDO globale du tissu s’écrit, pour chaque particule :
\[ \forall i, \quad \left\{ \begin{array}{l} \mathbf{p}_i'(t) = \mathbf{v}_i(t) \\[0.5em] \mathbf{v}_i'(t) = \mathbf{F}_i(\mathbf{p}, \mathbf{v}, t) / m_i \end{array} \right. \]
Pour un tissu de \(N \times N\) particules, on obtient un système couplé de \(6 N^2\) équations scalaires (3 pour la position, 3 pour la vitesse de chaque particule), à intégrer numériquement à chaque pas de temps.
Les forces de vent se modélisent simplement en ajoutant un terme \(\mathbf{F}_i^{\text{vent}}\) à la force totale : par exemple, une force constante orientée selon une direction donnée, modulée éventuellement par un bruit procédural pour simuler les rafales, ou un terme proportionnel à \(\mathbf{n}_i \cdot (\mathbf{v}_{\text{air}} - \mathbf{v}_i)\) où \(\mathbf{n}_i\) est la normale locale du tissu (permettant au vent de « pousser » les zones perpendiculaires à sa direction et de glisser sur les zones parallèles).
Un point souvent négligé en première approche est l’auto-collision du tissu : les ressorts seuls ne l’empêchent pas de se traverser lui-même. La gérer demande de tester les paires de triangles non adjacents à chaque pas de temps (avec une broad-phase pour rester praticable), puis d’appliquer une réponse en position ou en vitesse comme pour les sphères — c’est l’une des sources principales de complexité dans une implémentation robuste.
Reprenons le cas du ressort 1D isolé sans amortissement (pour lequel la solution exacte est l’oscillation harmonique parfaite). Si l’on intègre par Euler explicite, l’analyse de l’énergie révèle un comportement pathologique. L’énergie totale du système, somme cinétique + potentielle élastique, vaut :
\[ E = \frac{1}{2} m \, v^2 + \frac{K}{2} (p - l^0)^2 \]
À l’instant \(t^{k+1}\), après une étape d’Euler explicite (\(v^{k+1} = v^k - \frac{K}{m} \Delta t \, (p^k - l^0)\) et \(p^{k+1} = p^k + \Delta t \, v^k\)), on calcule l’énergie :
\[ E^{k+1} = \frac{1}{2} m \left( -\frac{K}{m} \Delta t \, (p^k - l^0) + v^k \right)^2 + \frac{1}{2} K \, (p^k + \Delta t \, v^k - l^0)^2 \]
En développant les deux carrés et en regroupant les termes, on aboutit à :
\[ E^{k+1} = \underbrace{\frac{1}{2} m \, (v^k)^2 + \frac{1}{2} K \, (p^k - l^0)^2}_{E^k} + \frac{1}{2} \left[ \underbrace{\frac{K^2}{m} (\Delta t)^2 \, (p^k - l^0)^2}_{> 0} \underbrace{- 2 K \Delta t \, (p^k - l^0) \, v^k + 2 K \Delta t \, (p^k - l^0) \, v^k}_{= 0} + \underbrace{K (\Delta t)^2 \, (v^k)^2}_{> 0} \right] \]
Les deux termes croisés s’annulent exactement, mais les deux termes carrés sont strictement positifs. On en déduit :
\[ E^{k+1} = E^k + \varepsilon \, (\Delta t)^2, \quad \varepsilon > 0 \]
L’énergie augmente donc à chaque pas de temps, d’une quantité proportionnelle à \((\Delta t)^2\). Le résultat est une divergence systématique : l’amplitude des oscillations croît sans borne, et la simulation explose à plus ou moins long terme. Réduire \(\Delta t\) ne fait que ralentir le phénomène ; cela ne le supprime pas.
Ce résultat est qualitativement vrai pour tout système oscillatoire : Euler explicite est inconditionnellement instable sur les EDO purement oscillantes. Pour le tissu, cela se traduit par des particules qui partent à l’infini après quelques secondes de simulation, même avec un pas de temps très petit. Il faut un schéma plus malin.
La solution la plus simple — et la plus utilisée en pratique en informatique graphique — est l’Euler semi-implicite, également connu sous le nom d’intégration de Verlet (en sa formulation positionnelle). L’astuce consiste à utiliser, dans la mise à jour de la position, la nouvelle vitesse \(\mathbf{v}^{k+1}\) plutôt que l’ancienne \(\mathbf{v}^k\).
Pour une EDO de la forme \(u'(t) = (\mathcal{F}_p(p, v, t), \mathcal{F}_v(p, v, t))\), on écrit :
\[ \left\{ \begin{array}{l} \mathbf{v}^{k+1} = \mathbf{v}^k + h \, \mathcal{F}_v(\mathbf{p}^k, \mathbf{v}^k, t^k) \\[0.5em] \mathbf{p}^{k+1} = \mathbf{p}^k + h \, \mathcal{F}_p(\mathbf{p}^k, \mathbf{v}^{k+1}, t^k) \end{array} \right. \]
qui se spécialise dans le cas mécanique classique \(\mathbf{p}'(t) = \mathbf{v}(t)\), \(m \mathbf{v}'(t) = \mathbf{F}(\mathbf{p}, t)\) en :
\[ \left\{ \begin{array}{l} \mathbf{v}^{k+1} = \mathbf{v}^k + h \, \mathbf{F}(\mathbf{p}^k, t^k) / m \\[0.5em] \mathbf{p}^{k+1} = \mathbf{p}^k + h \, \mathbf{v}^{k+1} \end{array} \right. \]
On voit que l’unique différence avec Euler explicite est le remplacement de \(\mathbf{v}^k\) par \(\mathbf{v}^{k+1}\) dans la seconde équation. La conversion d’une implémentation existante d’Euler explicite vers Euler semi-implicite est donc triviale, ce qui en fait une excellente première amélioration.
// Euler explicite (instable sur les ressorts)
v = v + h * F(p, t) / m;
p = p + h * v_old; // <-- utilise la vitesse précédente
// Euler semi-implicite (stable)
v = v + h * F(p, t) / m;
p = p + h * v; // <-- utilise la nouvelle vitesseEn substituant \(\mathbf{v}^k \simeq (\mathbf{p}^k - \mathbf{p}^{k-1}) / h\) dans le schéma semi-implicite, on peut éliminer complètement la vitesse de l’état :
\[ \mathbf{p}^{k+1} = 2 \, \mathbf{p}^k - \mathbf{p}^{k-1} + h^2 \, \mathbf{F}(\mathbf{p}, t) / m \]
Cette formulation, appelée intégration de Verlet au sens strict, ne stocke que les deux dernières positions (pas la vitesse). Elle est très utilisée en dynamique moléculaire et dans certains moteurs de jeu pour sa simplicité et sa compacité mémoire.
En termes de précision, le schéma semi-implicite est du premier ordre en position et en vitesse (comme Euler explicite ou Euler implicite), mais il possède une propriété cruciale : il est stable de manière conditionnelle sur les systèmes oscillants. L’énergie ne diverge plus ; elle reste bornée et oscille autour de la valeur exacte avec une petite erreur. Cette propriété est dite symplectique : le schéma préserve approximativement l’énergie d’un système hamiltonien (en moyenne sur un grand nombre de pas).
La condition de stabilité reste néanmoins contraignante : pour un ressort de raideur \(K\) et de masse \(m\), le pas de temps doit satisfaire \(h \lesssim 2 / \omega = 2 \sqrt{m/K}\), où \(\omega\) est la pulsation propre du ressort. Pour un système couplé comme un tissu, c’est la plus grande pulsation \(\omega_{\max}\) — typiquement portée par les ressorts les plus rigides (souvent les structurels ou les bending) — qui dicte la borne. Doubler la rigidité oblige donc à diviser le pas de temps par \(\sqrt{2}\), ce qui devient rapidement prohibitif pour des tissus très raides.
En pratique, pour la simulation de tissu et de masses-ressorts modérément rigides, Euler semi-implicite reste un excellent choix par défaut. Lorsque la borne sur \(h\) devient trop petite, on passe à des schémas implicites (Euler implicite, Newmark) qui demandent la résolution d’un système linéaire à chaque pas mais autorisent des pas de temps beaucoup plus grands. Ce compromis entre coût par pas et taille du pas est l’une des questions centrales de la simulation physique en informatique graphique.
L’animation d’un personnage articulé — un humain, un animal, une créature imaginaire — pose des problèmes qui n’apparaissent pas dans le rendu d’une scène statique. Le personnage doit pouvoir prendre n’importe quelle pose, sans qu’on ait à modéliser à la main chacune d’entre elles, et la déformation de sa surface (peau, vêtements collés au corps) doit suivre naturellement le mouvement des membres. Il faut également pouvoir spécifier l’animation à un niveau abstrait — « le pied gauche se pose ici », « le bras tend la main vers cet objet » — sans contraindre individuellement chacun des centaines ou milliers de sommets du maillage.
Deux concepts résolvent l’essentiel de ces difficultés. Le squelette d’animation réduit la pose du personnage à quelques dizaines de paramètres (les rotations articulaires), beaucoup plus maniables que le maillage complet. Le skinning définit comment la surface se déforme en fonction de ce squelette, en attachant chaque sommet à un ou plusieurs os. Une fois ces deux briques en place, on peut piloter l’animation par cinématique directe — en réglant les angles articulaires — ou par cinématique inverse — en spécifiant la position des extrémités et en laissant le solveur déduire les angles.
Un squelette d’animation est une structure hiérarchique de repères \(\mathrm{M}_i\) (chacun composé d’une position et d’une orientation), articulés les uns aux autres. La terminologie courante — empruntée à l’anatomie même si elle s’en éloigne — distingue :
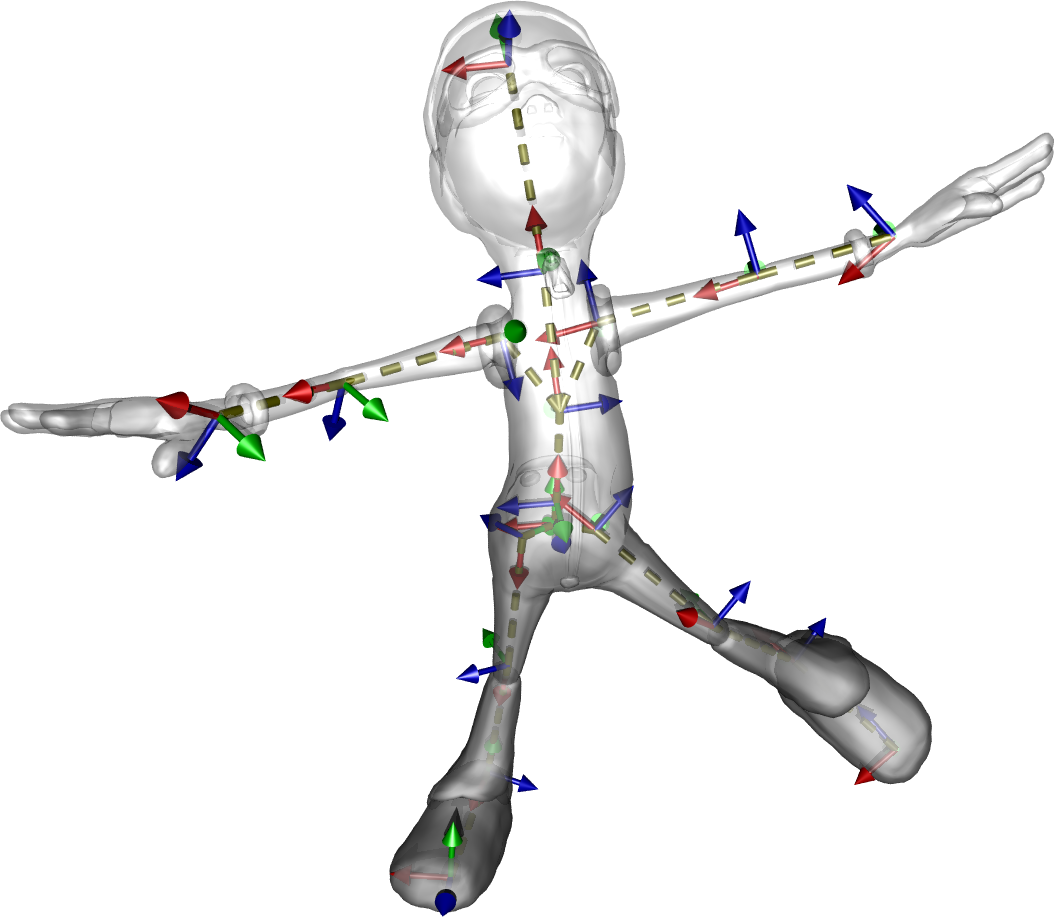

Un squelette d'animation est un ensemble de repères articulés. Il décrit les degrés de liberté du personnage, indépendamment de la géométrie de la peau.
Il faut souligner d’emblée que ce squelette n’a pas vocation à reproduire l’anatomie : un squelette de chat à des fins d’animation possède typiquement quelques dizaines d’articulations, là où l’anatomie réelle en compte des centaines. Son rôle est de capturer les degrés de liberté pertinents pour la pose et le mouvement, en restant suffisamment léger pour que l’animateur (ou un algorithme d’IK) puisse le manipuler en temps réel.
Le skinning rigide est l’approche la plus simple pour faire suivre la surface du personnage par le squelette. On attache chaque sommet du maillage à un os unique, et on lui applique la transformation rigide de cet os : si l’os tourne, le sommet tourne avec lui ; si l’os se translate, le sommet se translate également.
Skinning rigide : chaque sommet est associé à un os, et suit la transformation rigide du repère correspondant.
Pour formaliser cette déformation, on introduit la notion de pose de repos (bind pose) : la configuration de référence dans laquelle le squelette et le maillage ont été initialement modélisés. Notons \(\mathrm{M}^0\) le repère d’un os en pose de repos, et \(v^0\) la position d’un sommet attaché à cet os, exprimée dans le repère monde. Lorsque l’os passe à un nouveau repère \(\mathrm{M}\) (par animation), on cherche la nouvelle position \(v\) du sommet.
L’idée clé est que les coordonnées locales du sommet, exprimées dans le repère de l’os, ne changent pas : le sommet est solidaire de l’os, donc sa position relative au repère est fixe. On a donc :
\[ \mathrm{M}^{-1} \, v = (\mathrm{M}^0)^{-1} \, v^0 \]
(les deux expressions donnent les coordonnées locales du sommet, qui sont identiques par hypothèse). En multipliant à gauche par \(\mathrm{M}\), on obtient :
\[ v = \mathrm{M} \, (\mathrm{M}^0)^{-1} \, v^0 = \mathrm{T} \, v^0 \]
où \(\mathrm{T} = \mathrm{M} \, (\mathrm{M}^0)^{-1}\) est la matrice de transformation de l’os entre la pose de repos et la pose courante. Cette matrice est précalculée une fois par image (pour chaque os) puis appliquée à tous les sommets attachés à cet os.
Le skinning rigide est facile à mettre en œuvre et donne des résultats parfaits sur des objets eux-mêmes rigides (un robot articulé, une grue mécanique, un bras de pelleteuse). Pour un personnage organique, il pose en revanche un problème évident : aux articulations, où deux os se rencontrent, la transformation change brutalement d’un sommet à l’autre, créant des discontinuités visibles. Selon la direction du pli, le maillage se déchire (sur l’extérieur du coude) ou s’auto-intersecte (sur l’intérieur).


Artefacts typiques du skinning rigide aux articulations : discontinuités, auto-intersections, perte de volume.
L’idée naturelle pour résoudre ce problème est de mélanger les transformations au voisinage de chaque articulation, plutôt que de basculer brutalement de l’une à l’autre. C’est précisément ce que fait le smooth skinning, présenté dans la section suivante.
Le Linear Blend Skinning (LBS) est aujourd’hui la technique standard pour la déformation des personnages articulés, dans le cinéma comme dans les jeux vidéo. Son principe est une interpolation linéaire des positions calculées par le skinning rigide associé à chaque os voisin.

Considérons par exemple un sommet situé exactement entre deux os \(b_1\) et \(b_2\) (mi-chemin sur le coude d’un bras, par exemple). Plutôt que de l’attacher à un seul des deux, on calcule deux positions candidates — \(p_{|b_1} = \mathrm{T}_1 \, p^0\) via la transformation de \(b_1\), et \(p_{|b_2} = \mathrm{T}_2 \, p^0\) via celle de \(b_2\) — puis on en prend la moyenne :
\[ p = 0{,}5 \, p_{|b_1} + 0{,}5 \, p_{|b_2} = 0{,}5 \, \mathrm{T}_1 \, p^0 + 0{,}5 \, \mathrm{T}_2 \, p^0 = (0{,}5 \, \mathrm{T}_1 + 0{,}5 \, \mathrm{T}_2) \, p^0 \]
La dernière forme révèle une propriété remarquable du LBS : on peut moyenner les matrices de transformation plutôt que les positions, et appliquer la matrice mélangée à \(p^0\). Cela permet de précalculer une seule matrice par sommet par image, et de réutiliser le même code shader que pour le skinning rigide.
Pour le cas général d’un sommet \(i\) influencé par \(N\) os, on attribue à chaque os \(j\) un poids de skinning \(\alpha_{ij} \in [0, 1]\) vérifiant \(\sum_j \alpha_{ij} = 1\) (partition de l’unité). La position déformée s’écrit alors :
\[ p_i = \left( \sum_{j=0}^{N-1} \alpha_{ij} \, \mathrm{T}_j \right) p_i^0 = \left( \sum_{j=0}^{N-1} \alpha_{ij} \, \mathrm{M}_j \, (\mathrm{M}_j^0)^{-1} \right) p_i^0 \]

LBS appliqué à un éléphant : la même peau prend différentes poses sans apparition d'artefacts visibles aux articulations.
Le LBS doit son omniprésence à trois propriétés. Sa déformation est intuitive (chaque sommet suit le mélange visuel des os qui l’influencent). Sa forme est contrôlable par les poids — un artiste peut peindre des poids personnalisés pour ajuster localement le comportement. Et son coût est très faible : pour chaque sommet, il s’agit d’une moyenne pondérée de quelques matrices puis d’un produit matrice-vecteur, opérations parfaitement adaptées au GPU et exécutées dans le vertex shader. C’est pourquoi le LBS reste, près de quarante ans après son introduction par Magnenat-Thalmann et al. en 1988, le standard de fait dans l’industrie.
Le LBS a néanmoins des défauts connus — perte de volume au pliage extrême (effet candy wrapper lors d’une rotation à 180°), aplatissement des coudes — qui ont motivé de nombreuses variantes (dual-quaternion skinning, méthodes basées exemples, déformation par cages). Pour la grande majorité des animations courantes, ces défauts restent toutefois acceptables, et le LBS demeure le choix par défaut.
Reste la question pratique : d’où viennent les poids \(\alpha_{ij}\) ? Deux approches dominent.
La première consiste à les peindre manuellement. Les logiciels d’animation 3D (Blender, Maya, etc.) permettent à l’artiste de visualiser l’influence d’un os par un dégradé de couleur sur le maillage, et de la corriger au pinceau. Cette approche donne le meilleur contrôle artistique mais demande beaucoup de temps pour un personnage complexe.
La seconde approche calcule automatiquement les poids à partir d’une heuristique géométrique. La plus simple consiste à pondérer par l’inverse de la distance entre le sommet et chaque os. Pour deux os \(b_1\) et \(b_2\) aux distances \(d_1\) et \(d_2\) d’un sommet :
\[ \alpha_1 = \frac{d_1^{-1}}{d_1^{-1} + d_2^{-1}}, \quad \alpha_2 = \frac{d_2^{-1}}{d_1^{-1} + d_2^{-1}} \]
ce qui donne \(\alpha_1 = 1\) quand \(d_1 \to 0\) et chute rapidement à mesure que le sommet s’éloigne de \(b_1\). Cette formule est immédiate à généraliser à \(N\) os.
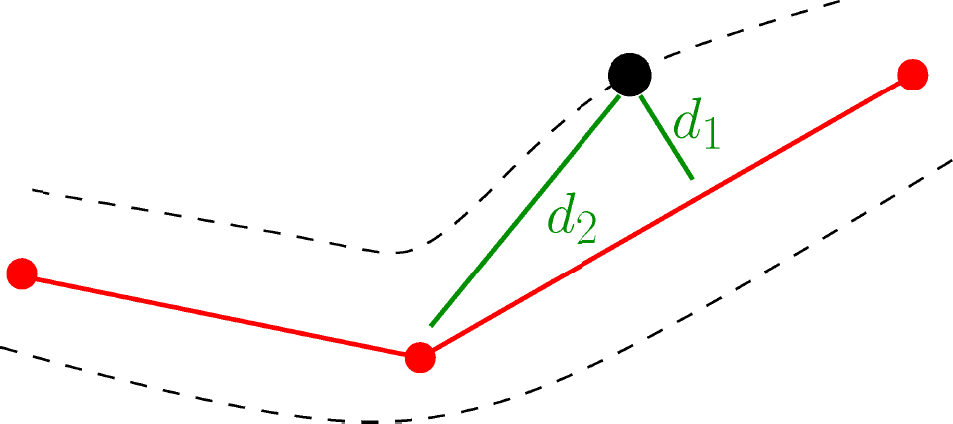
Pour des géométries complexes, on préfère des méthodes basées sur la diffusion d’une fonction harmonique sur le volume ou la surface du personnage, qui prennent en compte la connectivité du maillage et évitent que les poids « passent » à travers une cavité.

L’opération qui consiste à associer un squelette et des poids de skinning (ou plus généralement des poignées d’animation) à un maillage statique s’appelle le rigging. C’est typiquement une étape distincte du modeling (création de la géométrie) et de l’animation (mise en mouvement du squelette), confiée à un poste dédié dans les studios.
Un squelette d’animation est avant tout une structure hiérarchique : tous les enfants d’une articulation héritent de sa transformation, ce qui reflète la logique mécanique du corps (faire tourner l’épaule emporte le coude, le poignet, et la main). On désigne donc une articulation particulière comme racine de la hiérarchie — typiquement le bassin pour un humanoïde — d’où descendent tous les autres os par filiation.
Une telle représentation hiérarchique se prête naturellement à exprimer une pose en transformations relatives : « la cheville est inclinée de 20° par rapport au genou », « l’avant-bras forme un angle de 90° avec le bras ». C’est sous cette forme que les poses sont stockées dans les fichiers d’animation et manipulées par les animateurs : chaque articulation possède sa propre rotation locale, indépendamment de l’orientation absolue du personnage dans le monde.

Pour passer des transformations locales aux transformations globales (utilisées par le rendu et le skinning), on compose en remontant la hiérarchie. Avec des matrices \(4 \times 4\) homogènes, la formule est immédiate :
\[ \mathrm{M}^i_{\text{global}} = \mathrm{M}^{p(i)}_{\text{global}} \, \mathrm{M}^i_{\text{local}} \]
où \(p(i)\) désigne le parent de l’articulation \(i\). Si l’on préfère séparer rotation et translation (représentation utile pour interpoler les rotations sous forme de quaternion), la composition donne :
\[ R^i_{\text{global}} = R^{p(i)}_{\text{global}} \, R^i_{\text{local}}, \quad t^i_{\text{global}} = t^{p(i)}_{\text{global}} + R^{p(i)}_{\text{global}} \, t^i_{\text{local}} \]
L’encodage le plus simple d’un squelette en mémoire repose sur deux tableaux parallèles : un tableau de transformations locales, et un tableau d’indices indiquant le parent de chaque articulation (avec la convention \(-1\) pour la racine).

Geometry = [M0, M1, M2, M3, M4, M5]
Parent = [-1, 0, 1, 1, 0, 4]Une convention importante facilite l’implémentation : si l’on trie les articulations par ordre topologique (chaque articulation apparaît après son parent dans le tableau), la conversion local → global se fait en une seule passe linéaire :
// local, global : std::vector de structures { rotation r, translation p }
global[0] = local[0];
for (size_t k = 1; k < N; ++k) {
int parent = Parent[k];
global[k].r = global[parent].r * local[k].r;
global[k].p = global[parent].r * local[k].p + global[parent].p;
}À chaque itération, le parent a déjà été traité, donc
global[parent] contient bien la transformation globale du
parent. Cette convention de tri est respectée par la plupart des formats
d’animation (FBX, glTF, BVH), précisément pour permettre cette mise à
jour en \(O(N)\).
La cinématique directe (Forward Kinematics, FK) est la méthode la plus directe pour spécifier une animation : l’animateur règle manuellement l’angle de chaque articulation, et la position des extrémités s’en déduit par composition. C’est l’approche naturelle pour orienter une partie spécifique du corps — la tête, le bassin, un drapeau tenu à la main — où ce qui compte est l’orientation, pas une position cible précise.
Pour produire une animation continue, on définit des poses-clés à différents instants, et on interpole les rotations entre ces poses pour obtenir les états intermédiaires. C’est ici qu’apparaît un avantage parfois sous-estimé de la FK : interpoler une rotation autour d’une articulation (par exemple le coude) génère automatiquement une trajectoire courbe de l’extrémité (la main décrit un arc de cercle autour du coude). Pour des mouvements amples — un coup de poing, le balancement d’un bras pendant la marche — cette propriété produit des trajectoires naturelles sans effort de l’animateur.
La FK montre cependant ses limites dès qu’on cherche à imposer une position précise à une extrémité. Si l’on veut que le pied du personnage soit posé exactement sur une marche d’escalier, il est très difficile d’ajuster les angles de la hanche, du genou et de la cheville pour aboutir au bon résultat — d’autant que la moindre modification se propage à toute la chaîne. C’est précisément le rôle de la cinématique inverse.
La cinématique inverse (Inverse Kinematics, IK) résout le problème dual de la FK. Plutôt que de spécifier les angles articulaires et de calculer la position des extrémités, on spécifie la position (et éventuellement l’orientation) souhaitée d’un effecteur final — un point du squelette désigné comme cible, typiquement une main, un pied ou la tête — et on cherche les angles articulaires qui permettent d’atteindre cette position.
C’est le mode d’animation naturel pour la locomotion (les pieds doivent se poser à des endroits précis du sol) et pour la manipulation d’objets (la main doit attraper un objet précis dans la scène). Mathématiquement, en notant \(p_k\) la position de l’effecteur en bout de chaîne, on a la relation :
\[ p_k = p_0 + \sum_{i=0}^{k-1} l_i \, R_i \, u_i \]
où \(p_0\) est la position de la racine, \(l_i\) la longueur de l’os \(i\), \(u_i\) sa direction de référence, et \(R_i\) une matrice de rotation paramétrée (par exemple par des angles d’Euler, un axe-angle, ou un quaternion — le choix de paramétrisation influe sur le solveur mais pas sur la formulation). Le problème direct \(p_k = f(\theta_i)\) est immédiat à évaluer ; c’est l’inverse \(\theta_i = f^{-1}(p_k)\) qui est difficile.
Plusieurs propriétés rendent cette inversion non triviale. La fonction \(f\) est non linéaire (elle implique des compositions de rotations), il peut exister plusieurs solutions (un coude peut souvent atteindre la même position « par-dessus » ou « par-dessous »), il peut n’en exister aucune (la cible est hors de portée), et les solutions admises peuvent présenter des discontinuités lorsque la cible bouge (le coude bascule brusquement d’une position à l’autre). En conséquence, aucune formule en forme fermée n’existe en général : on doit recourir à des solveurs spécialisés.
Le cas particulier d’une chaîne à deux os (épaule + coude jusqu’à la main, ou hanche + genou jusqu’au pied) admet une solution analytique simple, qu’on peut dériver par trigonométrie. En se plaçant dans le plan défini par la chaîne et la cible, et en notant \(l_1, l_2\) les longueurs des deux os et \((x, y)\) la position cible relative à l’épaule, on obtient :
\[ \cos(\theta_1) = \frac{l_1^2 + x^2 + y^2 - l_2^2}{2 \, l_1 \, \sqrt{x^2 + y^2}}, \quad \cos(\theta_2) = \frac{l_1^2 + l_2^2 - (x^2 + y^2)}{2 \, l_1 \, l_2} \]
(la première ligne donne l’angle \(\theta_1\) du premier os par rapport à la direction épaule→cible, la seconde l’angle interne \(\theta_2\) entre les deux os, par application du théorème d’al-Kashi sur le triangle formé). Le signe du sinus correspondant à \(\theta_2\) donne les deux solutions (coude « au-dessus » ou « en dessous »), à choisir en fonction du contexte (typiquement par continuité avec la pose précédente).
Ce cas particulier est suffisamment fréquent (presque tous les membres humains ou animaux se ramènent à des chaînes à deux os : bras, jambe) pour qu’on l’implémente comme cas spécial dans les moteurs d’animation, en réservant les solveurs numériques aux chaînes plus longues ou aux contraintes additionnelles (orientation imposée de la main, par exemple). Plusieurs travaux étendent l’approche analytique à des configurations plus larges en imposant des paramétrisations spécifiques (Tolani 2000, Kallmann 2008), mais leur portée reste limitée à des morphologies bien spécifiques.
Pour les chaînes plus complexes, on linéarise localement le problème. La matrice jacobienne \(\mathrm{J}\) relie une petite variation des angles \(\Delta \theta\) à la variation correspondante de la position de l’effecteur \(\Delta p\) :
\[ \mathrm{J} \, \Delta \theta = \Delta p \]
Le système n’est pas carré en général (\(\mathrm{J}\) a typiquement plus de colonnes que de lignes : on a plus d’angles que de coordonnées de la cible, ce qui correspond à la redondance cinématique). On le résout par pseudo-inverse :
\[ \Delta \theta = \mathrm{J}^+ \, \Delta p, \quad \mathrm{J}^+ = \mathrm{J}^T \, (\mathrm{J} \, \mathrm{J}^T)^{-1} \]
où \(\mathrm{J}^+\) est la pseudo-inverse de Moore-Penrose, qui parmi toutes les solutions \(\Delta \theta\) choisit celle de norme minimale (le mouvement articulaire le plus petit). On peut également la calculer via la décomposition en valeurs singulières (SVD) :
\[ \mathrm{J}^+ = \mathrm{V} \, \Sigma^+ \, \mathrm{U}^T, \quad \Sigma^+_{ii} = \begin{cases} 1/\sigma_i & \text{si } \sigma_i \ne 0 \\ 0 & \text{sinon} \end{cases} \]
Au voisinage des singularités (configurations où la chaîne est étirée à fond, par exemple), certaines valeurs singulières \(\sigma_i\) tendent vers zéro et la pseudo-inverse explose, produisant des mouvements articulaires erratiques. On stabilise alors le solveur par la méthode des moindres carrés amortis (Damped Least Squares) :
\[ \Delta \theta = \mathrm{J}^T \, (\mathrm{J} \, \mathrm{J}^T + \lambda^2 \, \mathrm{I})^{-1} \, \Delta p \]
Le paramètre \(\lambda\) est un compromis : trop petit, le solveur reste instable près des singularités ; trop grand, il converge lentement loin de la cible. On l’ajuste typiquement de façon adaptative en fonction de la plus petite valeur singulière. Une fois \(\Delta \theta\) obtenu, on incrémente les angles, on évalue à nouveau l’erreur \(\Delta p\) vers la cible, et on itère jusqu’à convergence — c’est l’esprit des méthodes de Newton appliquées à l’IK.
Les méthodes basées Jacobienne sont précises mais coûteuses (résolution d’un système linéaire à chaque itération). Pour les besoins du temps réel — typiquement les jeux vidéo — on leur préfère souvent des méthodes heuristiques plus simples. La plus connue est la descente par coordonnées cycliques (Cyclic Coordinate Descent, CCD), introduite dans le contexte de l’animation par Jeff Lander en 1998.

L’algorithme fonctionne articulation par articulation, en partant de la dernière (juste avant l’effecteur) et en remontant vers la racine. À chaque articulation \(j^i\), on calcule la rotation qui aligne au mieux le segment (articulation, effecteur final) avec le segment (articulation, cible), et on l’applique. Une fois toutes les articulations traitées, l’effecteur est plus proche de la cible mais probablement pas dessus ; on relance alors une nouvelle itération depuis l’extrémité, et on continue jusqu’à convergence (typiquement quelques dizaines d’itérations).
CCD a plusieurs avantages : il ne nécessite aucune inversion matricielle, il est trivial à implémenter (quelques dizaines de lignes), et il converge de manière prévisible (utile pour garantir un coût borné par image dans un moteur de jeu). Sa convergence est en revanche linéaire (vs quadratique pour Newton), ce qui le rend lent loin de la cible, et il a tendance à privilégier les rotations près de l’extrémité (les articulations proches de la racine bougent peu), ce qui peut produire des poses peu naturelles.
FABRIK (Forward And Backward Reaching Inverse Kinematics), introduit par Aristidou et Lasenby en 2011, est une approche heuristique plus récente qui résout l’IK uniquement par des opérations sur les positions des articulations (sans manipuler explicitement les rotations), tout en respectant les longueurs des os.
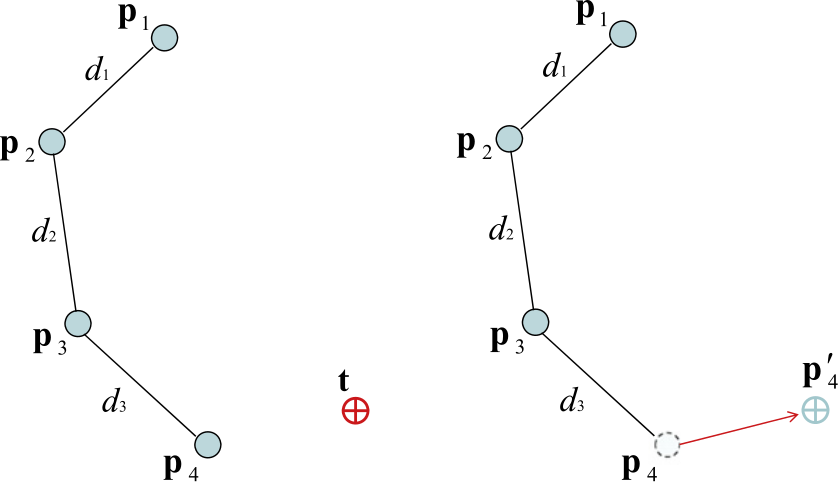
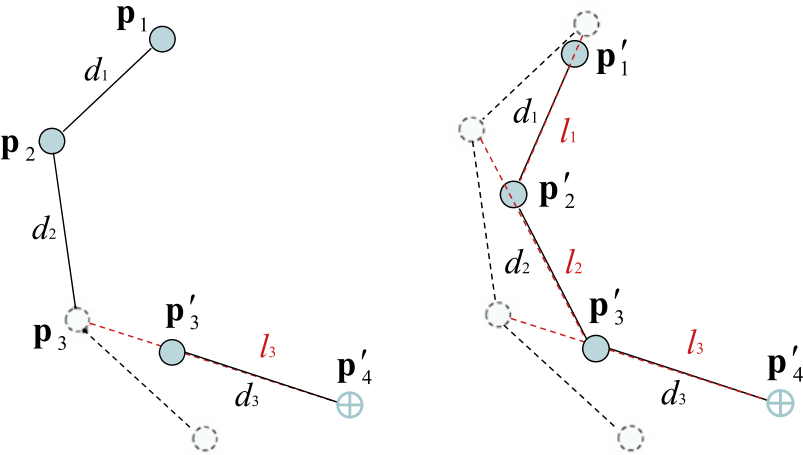
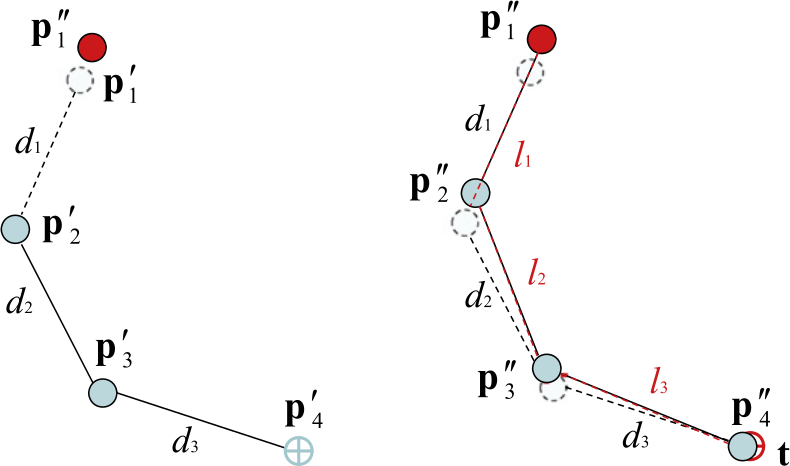
FABRIK : configuration initiale, passe avant (effecteur amené sur la cible, longueurs propagées vers la racine), passe arrière (racine ramenée à sa position d'origine, longueurs propagées vers l'effecteur).
Chaque itération consiste en deux passes. La passe avant déplace d’abord l’effecteur à la position cible, puis remonte la chaîne en repositionnant chaque articulation sur la droite reliant son successeur à la nouvelle position de l’enfant, à la distance imposée par la longueur de l’os. À l’issue de cette passe, les longueurs sont respectées et l’effecteur est sur la cible — mais la racine s’est déplacée, ce qui est inacceptable. La passe arrière part alors de la racine, la replace à sa position d’origine, puis descend la chaîne en repositionnant chaque articulation sur la droite reliant son prédécesseur à la nouvelle position du parent. À l’issue de cette seconde passe, la racine est de retour mais l’effecteur a été déplacé.
Plus formellement, en notant \(p_0, p_1, \ldots, p_N\) les positions des articulations (avec \(p_0\) la racine et \(p_N\) l’effecteur), \(l_i = \|p_{i+1} - p_i\|\) les longueurs imposées, et \(t\) la cible, l’algorithme s’écrit :
Entrées : positions p[0..N], longueurs ℓ[0..N−1], cible t,
tolérance ε, nombre max d'itérations k_max
p_racine ← p[0]
L ← ℓ[0] + ℓ[1] + … + ℓ[N−1]
# Cas 1 : cible hors de portée — étirer la chaîne en ligne droite vers t
si ‖t − p[0]‖ > L alors
pour i de 0 à N−1 faire
λ ← ℓ[i] / ‖t − p[i]‖
p[i+1] ← (1 − λ) · p[i] + λ · t
retourner p
fin si
# Cas 2 : cible atteignable — itérer passes avant et arrière
répéter au plus k_max fois
si ‖p[N] − t‖ < ε alors retourner p
# Passe avant : amener l'effecteur sur la cible
p[N] ← t
pour i de N−1 à 0 faire
λ ← ℓ[i] / ‖p[i+1] − p[i]‖
p[i] ← (1 − λ) · p[i+1] + λ · p[i]
# Passe arrière : remettre la racine en place
p[0] ← p_racine
pour i de 0 à N−1 faire
λ ← ℓ[i] / ‖p[i+1] − p[i]‖
p[i+1] ← (1 − λ) · p[i] + λ · p[i+1]
fin répéter
retourner pLe cœur de l’algorithme tient en deux lignes par étape : on calcule un coefficient \(\lambda = l_i / r\) (où \(r\) est la distance courante entre deux articulations consécutives), puis on déplace l’articulation par une simple interpolation linéaire qui rétablit la longueur \(l_i\). C’est cette simplicité — pas de matrice à inverser, pas de calcul d’angle, pas de résolution trigonométrique — qui fait toute la force de la méthode : chaque itération coûte \(O(N)\) opérations vectorielles, et l’algorithme se vectorise bien sur GPU.
Une fois les positions \(p_i\) obtenues, on en déduit les rotations articulaires par produit vectoriel ou par construction directe d’un repère orthonormé (en s’appuyant sur l’axe de l’os précédent et les contraintes d’orientation éventuelles), avant de réappliquer le LBS sur le maillage. Pour des chaînes ramifiées (squelette complet d’humanoïde avec deux bras et deux jambes), on traite chaque sous-chaîne indépendamment puis on réconcilie les positions au niveau des articulations partagées (épaules, hanches), en quelques itérations supplémentaires. Les contraintes d’angle se traitent dans la passe avant ou arrière en projetant la position calculée sur le cône autorisé par les limites articulaires.
En pratique, FABRIK converge en quelques itérations seulement, produit des poses visuellement naturelles, et se généralise bien aux contraintes articulaires (limites d’angle). C’est devenu l’un des solveurs IK les plus utilisés dans les moteurs de jeu modernes (Unreal Engine l’inclut directement sous le nom Two Bone IK / FABRIK Solver).
Les techniques abordées ici — FK, IK analytique, méthodes basées Jacobienne, CCD, FABRIK — couvrent l’essentiel de ce qu’un moteur d’animation utilise au quotidien. Au-delà, des approches plus avancées (motion capture combiné à du retargeting, blending de motion graphs, contrôleurs physiques pour la locomotion) permettent de produire des animations encore plus naturelles à partir de données réelles ou de simulations physiques pilotées — mais elles s’appuient toutes, à un moment ou à un autre, sur le squelette et le skinning décrits dans ce chapitre.